Join GitHub today
GitHub is home to over 28 million developers working together to host and review code, manage projects, and build software together.
Sign upAdding Apache Zeppelin to docker and documentation #259
Comments
This comment has been minimized.
Show comment
Hide comment
This comment has been minimized.
ruebot
Aug 13, 2018
Member
I'm almost certain Jupyter Notebook works fine on HEAD. Basic PySpark and Dataframe support was added back around April.
I think @ianmilligan1 has some basic documentation around this hanging around. We haven't published any of this on the site because we're waiting to get to our next release. Once that happens it wiil. But in the interim, all we really have is outlined in closed and open issues: 1.0.0 Release of AUT, DataFrames and PySpark.
|
I'm almost certain Jupyter Notebook works fine on HEAD. Basic PySpark and Dataframe support was added back around April. I think @ianmilligan1 has some basic documentation around this hanging around. We haven't published any of this on the site because we're waiting to get to our next release. Once that happens it wiil. But in the interim, all we really have is outlined in closed and open issues: 1.0.0 Release of AUT, DataFrames and PySpark. |
 ruebot
added
question
discussion
labels
ruebot
added
question
discussion
labels
Aug 20, 2018
This comment has been minimized.
Show comment
Hide comment
This comment has been minimized.
|
@SamFritz can you add this to our August 22nd agenda? |
This comment has been minimized.
Show comment
Hide comment
This comment has been minimized.
ianmilligan1
Aug 20, 2018
Member
|
|
This comment has been minimized.
Show comment
Hide comment
This comment has been minimized.
ianmilligan1
Aug 20, 2018
Member
thanks @Natkeeran - tested and you can see how it's running on my end here:
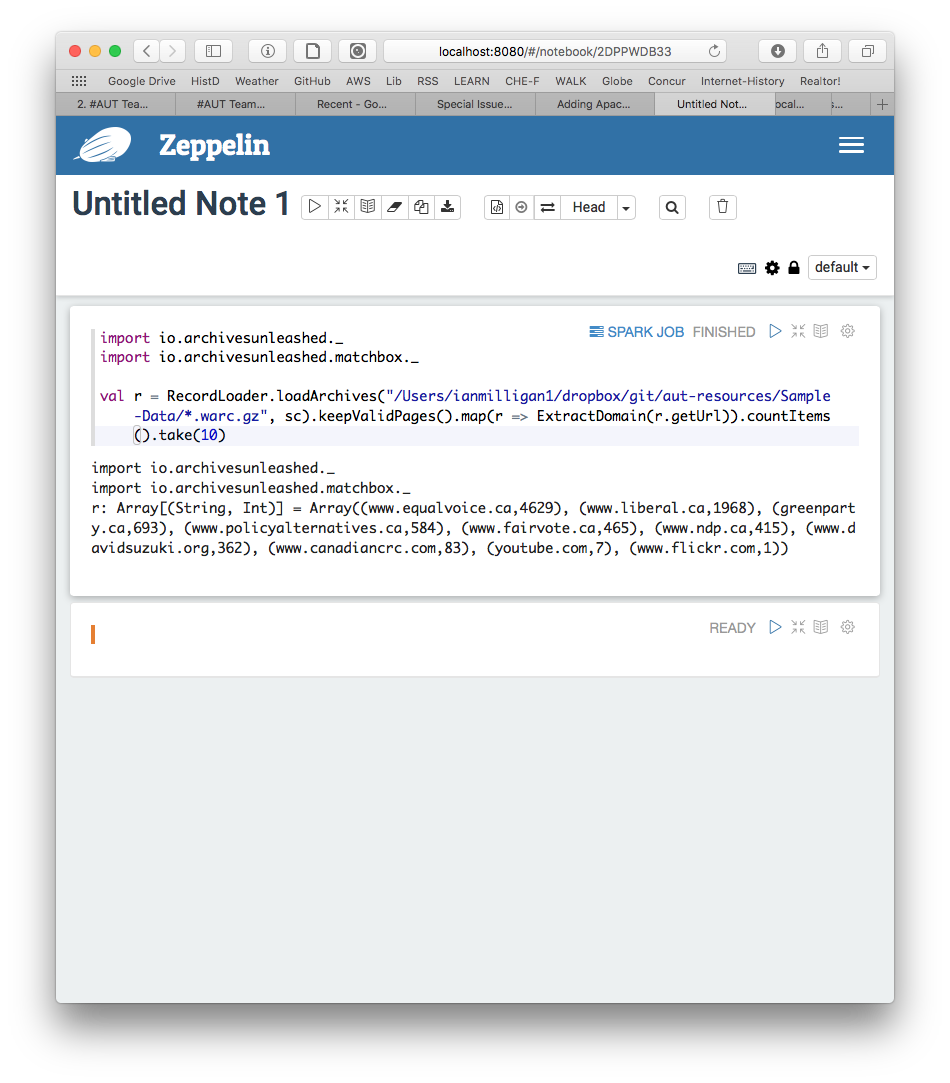
A few quick notes:
- I used the most recent build (i.e.
wget http://www-eu.apache.org/dist/zeppelin/zeppelin-0.8.0/zeppelin-0.8.0-bin-all.tgz) - on Mac, I didn't have to tinker with anything in
/optbut rather just edited thezeppelin-env.shfile in/conf
It's pretty straightforward except for editing the configuration file. We'll have to give some thought around how best to document that..
ianmilligan1
commented
Aug 20, 2018
•
edited
Edited 1 time
-
 ianmilligan1
edited
ianmilligan1
edited Aug 20, 2018 (most recent)
-
ianmilligan1
created Aug 20, 2018
edited
-
Aug 20, 2018 (most recent) -
Aug 20, 2018
|
thanks @Natkeeran - tested and you can see how it's running on my end here:
A few quick notes:
It's pretty straightforward except for editing the configuration file. We'll have to give some thought around how best to document that.. |
This comment has been minimized.
Show comment
Hide comment
This comment has been minimized.
ianmilligan1
Aug 20, 2018
Member
Oh, and scripts need to be compressed onto one line (the "paragraph" style we use with :paste in shell doesn't work, out of the box at least - I haven't dug deep to see if there is a workaround).
|
Oh, and scripts need to be compressed onto one line (the "paragraph" style we use with |
This comment has been minimized.
Show comment
Hide comment
This comment has been minimized.
Natkeeran
Aug 20, 2018
@ianmilligan1 Looks good. You can still use the paragraph style, but would need to add a brackets () as below.
val domains_list = (RecordLoader.loadArchives("/home/aut/data/*.gz", sc)
.keepValidPages()
.map(r => ExtractDomain(r.getUrl))
.countItems())
Natkeeran
commented
Aug 20, 2018
|
@ianmilligan1 Looks good. You can still use the paragraph style, but would need to add a brackets () as below. |
Natkeeran commentedAug 13, 2018
•
edited
Edited 4 times
-
 Natkeeran
edited
Natkeeran
edited Aug 13, 2018 (most recent)
-
 Natkeeran
edited
Natkeeran
edited Aug 13, 2018
-
 Natkeeran
edited
Natkeeran
edited Aug 13, 2018
-
 Natkeeran
edited
Natkeeran
edited Aug 13, 2018
-
 Natkeeran
created
Natkeeran
created Aug 13, 2018
Is your feature request related to a problem? Please describe.
AUT is a tool targeted towards researchers with limited technical expertise. Nevertheless, command line interactions can be a barrier for potential users. Many users in this domain are familiar with python notebooks and Apache Zeppelin provides similar workspaces and interactive mode of analysis.
Describe the solution you'd like
Installing Apache Zeppelin for experimental use is quite straightforward. Adding the instructions to documentation and including Zeppelin in aut docker would be useful. Down the road, Apache Zeppelin sandbox would be an easier way for users to evaluate AUT.
Describe alternatives you've considered
Additional context
Installing Apache Zeppelin (generally
/opt/zeppelin):Copy the default template:
Edit the zeppelin-env.sh and provide the following configuration parameters:
You can add additional park packages that may be useful for your analysis in SPARK_SUBMIT_OPTIONS.
Restart zeppelin
Go to 'http://localhost:8080/`.