Two weeks ago, I had the pleasure of attending the 17th International Semantic Web Conference held at Asiolomar Conference Grounds in California. A tremendously beautiful setting in a state park along the ocean. This trip report is somewhat later than normal because I took the opportunity to hang out for another week along the coast of California.
Before getting into the content of the conference, I think it’s worth saying, if you don’t believe that there are capable, talented, smart and awesome women in computer science at every level of seniority, the ISWC 2018 organizing committee + keynote speakers is the mike drop of counter examples:
Now some stats:
- 438 attendees
- Papers
- Research Track: 167 submissions – 39 accepted – 23% acceptance rate
- In Use: 55 submissions – 17 accepted – 31% acceptance rate
- Resources: 31 submissions – 6 accepted – 19% acceptance rate
- 38 Posters & 39 Demos
- 14 industry presentations
- Over 1000 reviews
These are roughly the same as the last time ISWC was held in the United States. So on to the major themes I took away from the conference plus some asides.
Knowledge Graphs as enterprise assets
It was hard to walk away from the conference without being convinced that knowledge graphs are becoming fundamental to delivering modern information solutions in many domains. The enterprise knowledge graph panel was a demonstration of this idea. A big chunk of the majors were represented:
The stats are impressive. Google’s Knowledge Graph has 1 billion things and 70 billion assertions. Facebook’s knowledge graph which they distinguish from their social graph and has just ramped up this year has 50 Million Entities and 500 million assertions. More importantly, they are critical assets for applications, for example, at eBay their KG is central to creating product pages, at Google and Microsoft, KGs are key to entity search and assistants, and at IBM they use it as part of their corporate offerings. But you know it’s really in-use when knowledge graphs are used for emoji:
It wasn’t just the majors who have or are deploying knowledge graphs. The industry track in particular was full of good examples of knowledge graphs being used in practice. Some ones that stood out were: Bosch’s use of knowledge graphs for question answering in DIY, multiple use cases for digital twin management (Siemens, Aibel); use in a healthcare chatbot (Babylon Health); and for helping to regulate the US finance industry (FINRA). I was also very impressed with Diffbot’s platform for creating KGs from the Web. I contributed to the industry session presenting how Elsevier is using knowledge graphs to drive new products in institutional showcasing and healthcare.
Beyond the wide use of knowledge graphs, there was a number of things I took away from this thread of industrial adoption.
- Technology heterogeneity is really the norm. All sorts of storage, processing and representation approaches were being used. It’s good we have the W3C Semantic Web stack but it’s even better that the principles of knowledge representation for messy data are being applied. This is exemplified by Amazon Neptune’s support for TinkerPop & SPARQL.
- It’s still hard to build these things. Microsoft said it was hard at scale. IBM said it was hard for unique domains. I had several people come to me after my talk about Elsevier’s H-Graph discussing similar challenges faced in other organizations that are trying to bring their data together especially for machine learning based applications. Note, McCusker’s work is some of the better publicly available thinking on trying to address the entire KG construction lifecycle.
- Identity is a real challenge. I think one of the important moves in the success of knowledge graphs was not to over ontologize. However, record linkage and thinking when to unify an entity is still not a solved problem. One common approach was towards moving the creation of an identifiable entity closer to query time to deal with the query context but that removes the shared conceptualization that is one of the benefits of a Knowledge Graph. Indeed, the clarion call by Google’s Jamie Taylor to teach knowledge representation was an outcome of the need for people who can think about these kinds of problem.
In terms of research challenges, much of what was discussed reflects the same kinds of ideas that were discussed at the recent Dagstuhl Knowledge Graph Seminar so I’ll point you to my summary from that event.
Finally, for most enterprises, their knowledge graph(s) were considered a unique asset to the company. This led to an interesting discussion about how to share “common knowledge” and the need to be able to merge such knowledge with local knowledge. This leads to my next theme from the conference.
Wikidata as the default option
When discussing “common knowledge”, Wikidata has become a focal point. In the enterprise knowledge graph panel, it was mentioned as the natural place to collaborate on common knowledge. The mechanics of the contribution structure (e.g. open to all, provenance on statements) and institutional attention/authority (i.e. Wikimedia foundation) help with this. An example of Wikidata acting as a default is the use of Wikidata to help collate data on genes
Fittingly enough, Markus Krötzsch and team won the best in-use paper with a convincing demonstration of how well semantic technologies have worked as the query environment for Wikidata. Furthermore, Denny Vrandečić (one of the founders of Wikidata) won the best blue sky paper with the idea of rendering Wikipedia articles directly from Wikidata.
Deep Learning diffusion
As with practically every other conference I’ve been to this year, deep learning as a technique has really been taken up. It’s become just part of the semantic web researchers toolbox. This was particularly clear in the knowledge graph construction area. Papers I liked with DL as part of the solution:
- EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs
- QA4IE: A Question Answering Based Framework for Information Extraction
- Inducing Implicit Relations from Text Using Distantly Supervised Deep Nets
- A Novel Ensemble Method for Named Entity Recognition and Disambiguation based on Neural Network
- Measuring semantic coherence of a conversation
While not DL per sea , I’ll lump embeddings in this section as well. Papers I thought that were interesting are:
- Aligning Knowledge Base
and Document Embedding Models Using Regularized Multi-Task Learning - An embedding based approach to ontologies
- Towards Empty Answers in SPARQL: Approximating Querying with RDF Embedding
- Rule Learning from Knowledge Graphs Guided by Embedding Models
The presentation of the above paper was excellent. I particularly liked their slide on related work:
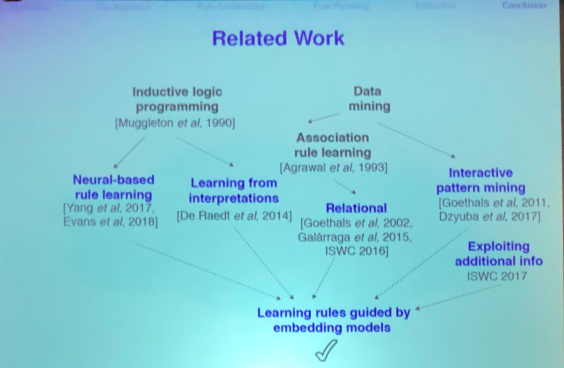
As an aside, the work on learning rules and the complementarity of rules to other forms of prediction was an interesting thread in the conference. Besides the above paper, see the work from Heiner Stuckenschmidt’s group on evaluating rules and embedding approaches for knowledge graph completion. The work of Fabian Suchanek’s group on the representativeness of knowledge bases is applicable as well in order to tell whether rule learning from knowledge graphs is coming from a representative source and is also interesting in its own right. Lastly, I thought the use of rules in Beretta et al.’s work to quantify the evidence of an assertion in a knowledge graph to help improve reliability was neat.
Information Quality and Context of Use
The final theme is a bit harder for me to solidify and articulate but it lies at the intersection of information quality and how that information is being used. It’s not just knowing the provenance of information but it’s knowing how information propagates and was intended to be used. Both the upstream and downstream need to be considered. As a consumer of information I want to know the reliability of the information I’m consuming. As a producer I want to know if my information is being used for what it was intended for.
The later problem was demonstrated by the keynote from Jennifer Golbeck on privacy. She touched on a wide variety of work but in particular it’s clear that people don’t know but are concerned with what is happening to their data.
There was also quite a bit of discussion going on about the decentralized web and Tim Berners-Lee’s Solid project throughout the conference. The workshop on decentralization was well attended. Something to keep your eye on.
The keynote by Natasha Noy also touched more broadly on the necessity of quality information this time with respect to scientific data.
The notion of propagation of bias through our information systems was also touched on and is something I’ve been thinking about in terms of data supply chains:
That being said I think there’s an interesting path forward for using technology to address these issues. Yolanda Gil’s work on the need for AI to address our own biases in science is a step forward in that direction. This is a slide from her excellent keynote at SemSci Workshop:

All this is to say that this is an absolutely critical topic and one where the standard “more research is needed” is very true. I’m happy to see this community thinking about it.
Final Thought
The Semantic Web community has produced a lot (see this slide from Nataha’s keynote:

ISWC 2018 definitely added to that body of knowledge but more importantly I think did a fantastic job of reinforcing and exciting the community.
Random Notes
- You should read Helena Deus’s trip report as well.
- Also a twitter summary of ISWC 2018 from Svitlana Vakulenko
- What I said about ISWC 2017
- Ada Lovelace Day
- Food + Knowledge Graphs – Yummy!
- Provenance
- ProvBook – by directional conversation of Juypter Notebooks and RDF including temporal provenance of cells
- Pretty excited about the WebIsALOD in general and as a database of provenance.
- Cool to see provenance being used to improve SPARQL query performance.
- Crowdsourcing:
- Mike Lauruhn presented our work on case studies for trying to determine good composition for the crowd correctly
- Really enjoyed the Crowd Truth tutorial. A case study in open data. We spent time trying to apply their measures to my data.
My keynote at SemSci Workshop – The Challenge of Deeper Knowledge Graphs for Science











{kind=link}