Join GitHub today
GitHub is home to over 36 million developers working together to host and review code, manage projects, and build software together.
Sign upIngest: Provide more robust ingest for Excel and CSV #585
Comments
 eaquigley
added this to the
Dataverse 4.0: In Review milestone
eaquigley
added this to the
Dataverse 4.0: In Review milestone
Jul 9, 2014
eaquigley
assigned
posixeleni
Jul 9, 2014
 scolapasta
modified the milestones:
Beta 3 - Dataverse 4.0,
In Review - Dataverse 4.0
scolapasta
modified the milestones:
Beta 3 - Dataverse 4.0,
In Review - Dataverse 4.0
Jul 15, 2014
eaquigley
modified the milestones:
Beta 3 - Dataverse 4.0,
Beta 5 - Dataverse 4.0
Aug 19, 2014
eaquigley
modified the milestones:
Beta 5 - Dataverse 4.0,
Beta 6 - Dataverse 4.0
Aug 27, 2014
This comment has been minimized.
This comment has been minimized.
|
@posixeleni Any update on this? |
This comment has been minimized.
This comment has been minimized.
|
@eaquigley Will need to review the documentation mentioned above to see if it can help. @landreev have you had any luck with this? |
 posixeleni
modified the milestones:
Beta 8 - Dataverse 4.0,
Beta 6 - Dataverse 4.0
posixeleni
modified the milestones:
Beta 8 - Dataverse 4.0,
Beta 6 - Dataverse 4.0
Sep 12, 2014
This comment has been minimized.
This comment has been minimized.
|
Will need to move this to another milestone. |
posixeleni
modified the milestones:
Dataverse 4.0: Final,
Beta 8 - Dataverse 4.0,
Beta 10 - Dataverse 4.0
Oct 15, 2014
posixeleni
assigned
scolapasta
and unassigned
posixeleni
Oct 15, 2014
This comment has been minimized.
This comment has been minimized.
|
@kcondon @landreev Found some best practices on how we can ingest Excel files https://oit.utk.edu/research/documentation/Documents/HowToUseExcelForDataEntry.pdf but not sure if these would be applied across the board by all researchers and how we would handle them exactly in Dataverse:
@eaquigley Assigning to @scolapasta to see if this is something we can schedule for 4.0 or if it needs to be moved to 4.1. |
scolapasta
modified the milestones:
In Review - Dataverse 4.0,
Beta 10 - Dataverse 4.0
Dec 3, 2014
This comment has been minimized.
This comment has been minimized.
|
Probably best to just move this to 4.1, but first checking with @landreev if there are any low hanging fruit here |
scolapasta
assigned
landreev
and unassigned
scolapasta
Jan 6, 2015
scolapasta
modified the milestones:
Beta 11 - Dataverse 4.0,
In Review - Dataverse 4.0
Jan 6, 2015
scolapasta
modified the milestones:
Beta 11 - Dataverse 4.0,
Dataverse 4.0: Final
Jan 23, 2015
This comment has been minimized.
This comment has been minimized.
|
Just ran into a guide from Cornell about preparing tabular data for archiving: https://data.research.cornell.edu/content/tabular-data. (Looked but couldn't find anything similar at Harvard.) Could be helpful if we decided to improve the docs. |
This comment has been minimized.
This comment has been minimized.
|
This is a nice documentation piece, but it's written too much from only the
perspective of archiving, for what we need. I agree that the docs should
include this type of documentation on working with files, and files to
upload, but we should write from the point of view of a researcher or data
author - a researcher working with quantitative data usually will already
work with R, stata or similar data package. If he/she doesn't use any of
those, recommending what you should do when creating the CSV file can be
helpful.
Let's discuss this - it would be a very useful exercise to write this as
part of the docs.
Merce
…----------
Mercè Crosas, Ph.D., Chief Data Science and Technology Officer, IQSS, Harvard
University
@mercecrosas mercecrosas.com
On Tue, Feb 7, 2017 at 4:37 PM, Julian Gautier ***@***.***> wrote:
Just ran into a guide from Cornell about preparing tabular data for
archiving: https://data.research.cornell.edu/content/tabular-data
<https://urldefense.proofpoint.com/v2/url?u=https-3A__data.research.cornell.edu_content_tabular-2Ddata&d=CwMFaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=nPWg2rii7w3D3xfGqiBflbCOe1evplsYGXY2WfYAB9Y&s=lYQrq__64UAge9bPijJP4y7ulEy53ZHYYMIzvA4czsE&e=>.
(Looked but couldn't find anything similar at Harvard.) Could be helpful if
we decided to improve the docs.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_IQSS_dataverse_issues_585-23issuecomment-2D278148359&d=CwMFaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=nPWg2rii7w3D3xfGqiBflbCOe1evplsYGXY2WfYAB9Y&s=c3uC5537VLE_ADyX-vNg_qZHlkq8PWelNatDqnN8yM8&e=>,
or mute the thread
<https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_notifications_unsubscribe-2Dauth_AApQyH5khQ9-5FmH9e00Xcf6PG7JWtWeSPks5raOQbgaJpZM4CLnV5&d=CwMFaQ&c=WO-RGvefibhHBZq3fL85hQ&r=n9HCCtgqDPssu5vpqjbO3q4h2g6vMeTOp0Ez7NsdVFM&m=nPWg2rii7w3D3xfGqiBflbCOe1evplsYGXY2WfYAB9Y&s=9sofGdEA35Scnz6bmI4gX6MyXiHoTAqwsiqk7s8jZHY&e=>
.
|
 pdurbin
referenced this issue
pdurbin
referenced this issue
Mar 8, 2017
Closed
200+ files uploaded to Harvard Dataverse failed ingest during one month in 2017 #3675
This comment has been minimized.
This comment has been minimized.
|
In a Slack conversation with @thegaryking about better support for CSV ingest, @landreev wrote:
|
This comment has been minimized.
This comment has been minimized.
|
Have you considered delegating CSV support to external libraries like Apache Commons CSV? I see it is listed as a dependency for Dataverse, but the ingest apparently still depends on @landreev's own code. |
This comment has been minimized.
This comment has been minimized.
|
@bencomp I'm not sure why we invented our own way of parsing CSV files within the Dataverse code base. I agree with you that if we can leverage an open source package that already does this job, it would probably be better. Maybe there's some Dataverse-specific stuff in our CSV parsing. I don't know. @landreev would. Yesterday @raprasad was showing us how Python's Pandas can parse Excel files: https://github.com/IQSS/miniverse/blob/729a8d1cb0bededbcc9882e51ccf5b874b1a178e/dv_apps/datafiles/tabular_previewer.py#L107 There's also a suggestion to have ingest run on a separate service rather than as part of the Dataverse monolith: #2331. |
This comment has been minimized.
This comment has been minimized.
|
There was some historical reason why we insisted on one line per one observation requirement. But it doesn't appear to be relevant anymore. |
This comment has been minimized.
This comment has been minimized.
|
I'm opening a new issue for some concrete incremental improvements of the CSV ingest, to be estimated and included into some sprint in the short term. (This one is just too generic) |
This comment has been minimized.
This comment has been minimized.
|
#3767 - a child issue I created just for rewriting the CSV plugin to use more standard (and permissive) parsing. |
pdurbin
added
Feature: File Upload & Handling
and removed
Component: Documentation
labels
Jun 9, 2017
pdurbin
added
the
User Role: Depositor
label
Jul 4, 2017
This comment has been minimized.
This comment has been minimized.
|
Does #3767 close this? |
pdurbin
referenced this issue
Aug 10, 2017
Open
Ingest: Excel ingest can't accept more than 26 (Z) columns. #3382
This comment has been minimized.
This comment has been minimized.
adam3smith
commented
Mar 7, 2018
|
I have two additions on this -- there are a couple of tickets on Excel ingest, this seemed the most appropriate one but please redirect if I missed something
|
This comment has been minimized.
This comment has been minimized.
|
@adam3smith thanks, these are related: |
 adam3smith
referenced this issue
adam3smith
referenced this issue
Mar 7, 2018
Open
Switch preservation format extension from .tab to .tsv #2720
This comment has been minimized.
This comment has been minimized.
adam3smith
commented
Mar 7, 2018
|
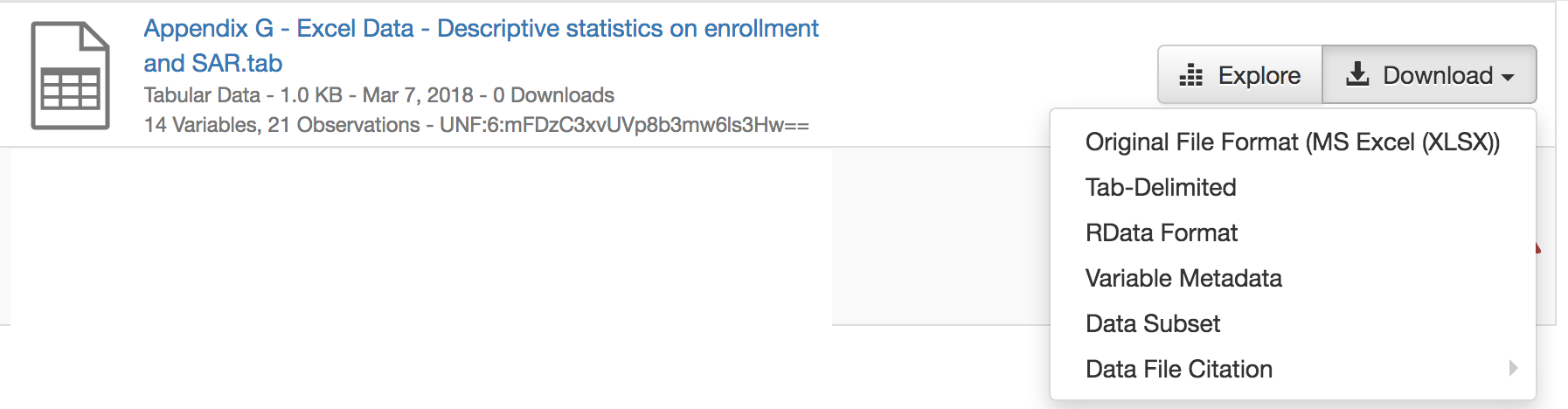
Great. #2720 addresses what I want with 1. but while I agree with Alex in #4000 , my point about Excel is different: the original format is completely lost when uploading Excel. I have no way to get out the Excel file I uploaded after ingest (at least I'm not finding it). That may actually be a bug? |
This comment has been minimized.
This comment has been minimized.
|
Hi @adam3smith. The second point sounds like a bug. Could you link to a dataset with an ingested Excel file where we're not able to download the original format? This quick search returns a few ingested Excel files in Harvard Dataverse (4.8.4), but I'm able to download the original format for them: https://dataverse.harvard.edu/dataverse/harvard?q=fileName%3Aexcel&fq0=fileTypeGroupFacet%3A%22tabulardata%22. I just uploaded an .xlsx file on Harvard Dataverse that ingested and was able to download the original file format.
|
This comment has been minimized.
This comment has been minimized.
adam3smith
commented
Mar 7, 2018
|
Sorry for the false alarm -- this works correctly for me not just in demo.dataverse but also in our dev instance on 4.8. It seems broken the way I describe, though, in our beta environment running 4.6.2. So may have gotten fixed at some point? |
This comment has been minimized.
This comment has been minimized.
|
@adam3smith there were a lot of ingest improvements included in our 4.8 release, which could account for improved functionality between demo (4.8.4) and your 4.6.2. |
 djbrooke
added this to Inbox 🗄
in IQSS/dataverse
djbrooke
added this to Inbox 🗄
in IQSS/dataverse
May 8, 2019
This comment has been minimized.
This comment has been minimized.
|
Since this issue was opened, it has been addressed for the CSV ingest plugin, that was much improved. |
This comment has been minimized.
This comment has been minimized.
|
@landreev yeah, I agree that this issue should probably be closed. It's one of our oldest open issues and doesn't fit into our modern "small chunks" style. #3382 ("Excel ingest can't accept more than 26 (Z) columns") is an example of a small chunk and @qqmyers make pull request #5891 for it yesterday. (Thank you!! @adam3smith you seem to be fairly engaged in this issue. Are you willing or able to create a "small chunk" issue or two for some of your ideas above? Everyone else is very welcome to create new issues as well, of course! The idea is that the issues should be relatively small and targeted. Incremental improvement. Small chunks. |
This comment has been minimized.
This comment has been minimized.
|
@pdurbin @landreev I opened this issue originally because the initial implementation was very basic because we did not have a good idea of what a set of features we should support would be, given the wide variety of practices. It was, at least initially, a research spike to figure that out, then become something specific. We lucked out there was a csv implementation so I agree that part is resolved. I think Leonid's suggestion of opening a new Excel-specific implementation sounds reasonable and I'm happy it has specifics since when I opened this there was not an agreed upon set of specifics. So, 1. open new ticket with specifics, then 2. close this ticket ;) |
eaquigley commentedJul 9, 2014
Author Name: Kevin Condon (@kcondon)
Original Redmine Issue: 4014, https://redmine.hmdc.harvard.edu/issues/4014
Original Date: 2014-05-21
Original Assignee: Eleni Castro
The initial Excel ingest implementation is a proof of concept -it supports rectangular columns and rows of string and numeric types.
More functionality may be required, for example dates, missing value support, variable labels, but it is unclear what is typically expected from researchers who use Excel to store their data.
This ticket is a place holder to investigate a concrete set of requirements for a more robust Excel ingest.
As a side note, there are a number of "How to use Excel for Research Data" guides posted by various universities out there that may answer some questions and provide a starting point.