Join GitHub today
GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together.
Sign upAdd Audio & Video binary extraction #341
Conversation
ruebot
added some commits
Aug 12, 2019
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
codecov
bot
commented
Aug 13, 2019
•
Codecov Report
@@ Coverage Diff @@
## master #341 +/- ##
==========================================
+ Coverage 73.49% 74.91% +1.42%
==========================================
Files 39 39
Lines 1147 1216 +69
Branches 198 224 +26
==========================================
+ Hits 843 911 +68
+ Misses 237 214 -23
- Partials 67 91 +24
Continue to review full report at Codecov.
|

ruebot
added some commits
Aug 13, 2019
This comment has been minimized.
This comment has been minimized.
|
Cleaned up the filename and extension extraction, seems to work well most of the time on PDFs and audio files. Struggles more on video files. Might be worth exploring combining this method with @jrwiebe's work over on the this branch. I also tried ripping out the big block of OR conditionals on the audio and video extraction, and hit some problems with my tests. I think those OR conditionals are what's actually doing all the work, and the ...I'll loop back around to that tomorrow or Wednesday. |
This comment has been minimized.
This comment has been minimized.
|
I think this is why we're having problems with I'm going to try some tests with |
This comment has been minimized.
This comment has been minimized.
|
If we're filtering for |
This comment has been minimized.
This comment has been minimized.
|
@jrwiebe it's why the test is failing if I remove all the OR conditionals. The test isn't getting the one match in the |
This comment has been minimized.
This comment has been minimized.
|
But are the other assertions -- e.g., URL, MD5 hash -- evaluating as true? |
This comment has been minimized.
This comment has been minimized.
|
Yes |
This comment has been minimized.
This comment has been minimized.
|
Generic mime type results are what I was getting before I made Tika should be returning "video/mp4" when detecting that file: Obviously AUT isn't using |
jrwiebe
added some commits
Aug 13, 2019
This comment has been minimized.
This comment has been minimized.
|
Nope, ignore what I said, my theory is wrong. Note the change in the number of bytes: I just pushed a fix to this. It's based on Update: I took the liberty of merging my fix with this branch. |
jrwiebe
added some commits
Aug 13, 2019
 jrwiebe
marked this pull request as ready for review
jrwiebe
marked this pull request as ready for review
Aug 13, 2019
jrwiebe
reviewed
Aug 13, 2019
This comment has been minimized.
This comment has been minimized.
|
I can test on sample data as well - should I test using the same scripts that @ruebot originally provided above? |
This comment has been minimized.
This comment has been minimized.
|
Yes. Those should work; it's worth verifying. The new unit tests @ruebot wrote are succeeding, so I'm pretty confident in this PR, but since Nick initiated it I just thought he should have a say on my changes. |
ruebot
reviewed
Aug 13, 2019
| @@ -655,7 +655,7 @@ | |||
| <!-- see issue #302 | |||
| <groupId>org.apache.tika</groupId> | |||
| --> | |||
| <groupId>com.github.archivesunleashed.tika</groupId> | |||
| <groupId>com.github.jrwiebe.tika</groupId> | |||
This comment has been minimized.
This comment has been minimized.
ruebot
Aug 13, 2019
Author
Member
We can fix this after this is merged. We're working on sorting JitPack builds/releases now.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
Testing looks good on my end. Here's the results for the three overall tests with 10 GeoCities WARCs: Original state of PR r.getMimeType Jeremy's updates @ianmilligan1 feel free to test on whatever data you have. If you want these 10 WARCs, let me know and I'll get them to you. I'll also open up a couple side issues once this is merged for file extensions for unknown, and adding additional MimeType columns. When you're good, let me know, and I'll write up a commit message for you to merge. |
ianmilligan1
approved these changes
Aug 13, 2019
|
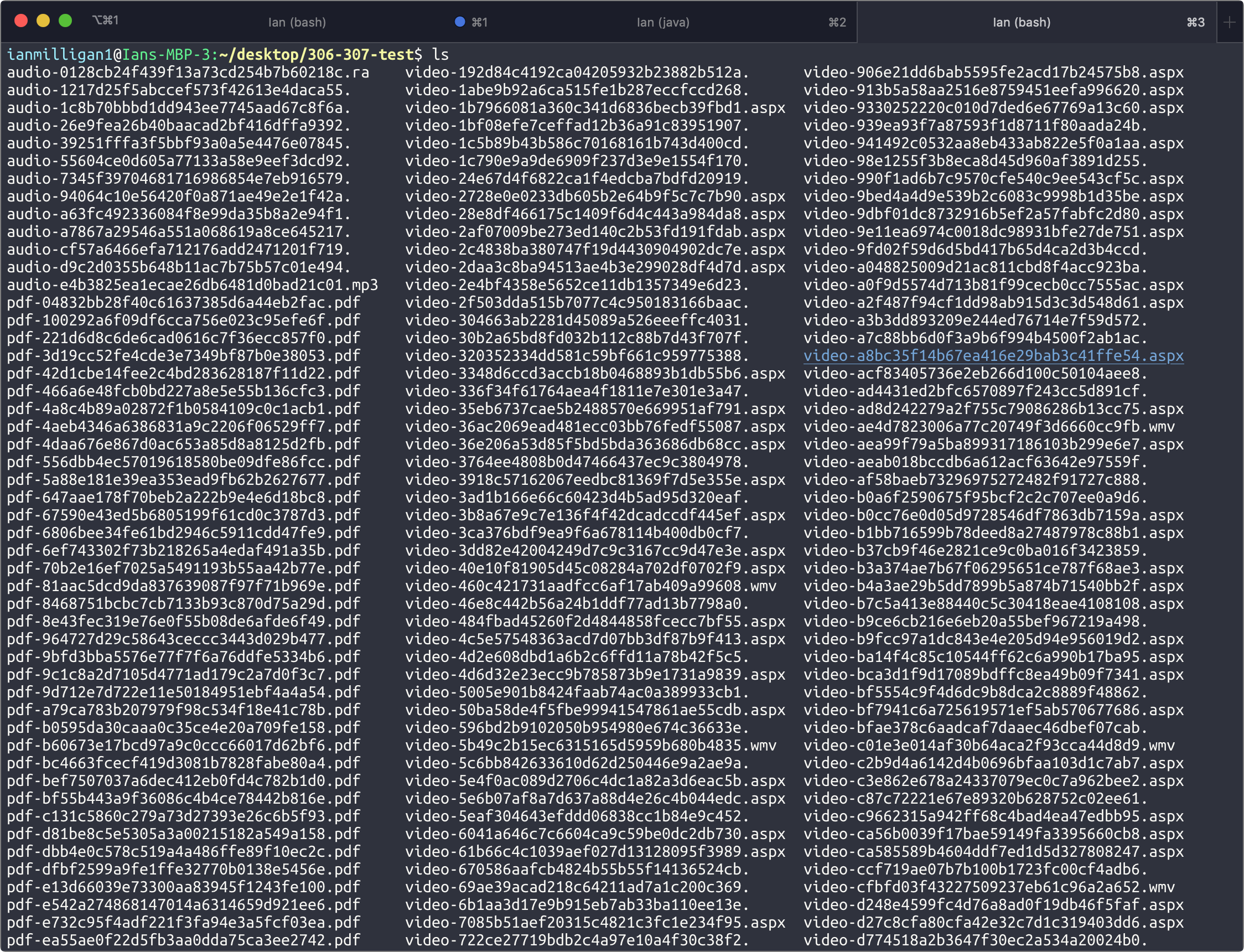
Tested on the sample data from aut-resources and successfully extracted PDFs, audio, and video. Still quite a few missing extensions, as seen below, which will be addressed in #343. The
|
ruebot commentedAug 13, 2019
GitHub issue(s):
What does this Pull Request do?
saveToDiskto use file extension from TikaHow should this be tested?
Pull down the branch, and do something along these lines (I had memory issues, so I did my whole Spark config thing):
306-pdf-audio-video-extract.scala
I have a whole lot of audio, pdf, and video files.
Additional Notes:
UNKNOWN? Do we want that stored in the dataframe, or done on the fly insaveToDisk?@jrwiebe @lintool @ianmilligan1 let me know what you think.