Join GitHub today
GitHub is home to over 50 million developers working together to host and review code, manage projects, and build software together.
Sign upHeap space!! java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3332) #317
Comments
|
@jrwiebe @lintool @ianmilligan1 finally wrote it up. Let me know if I missed anything, or y'all want me to provide more info. |
|
@ruebot, you say:
Can you clarify this? Are you saying that jobs run with the same parameters against other large collections – in terms of total archive size – do not result in heap space errors? Because in my testing I didn't find this to be the case. It seemed like the error was rather a function of the total size of all the WARCs being operated on simultaneously. I think I was seeing jobs bail when they didn't have about 4 times the amount of memory as I found this garbage collection log analyzer useful for trying to understand how memory was being used, though I'm still puzzled that so much memory is being used. See for example how much memory is used by a job that simply chains To generate garbage collection logs you want to do something like this (the For the record, I'm pretty certain KryoSerializer doesn't offer any benefits for this problem; I just kept using it because I copied @ruebot's command line. I ran tests with and without some of the other tuning options as well, and was seeing similar results. |
|
Sorry, yeah, that's kinda vague. I meant overall, we've analyzed 170T of collections ranging from under a 1G of WARCs up to 12T with the same basic Spark settings. I added the KryoSerializer during troubleshooting because it looked like it got further along in some cases, and reading up on it, it made sense at the time. Thanks for putting in the GC info. I was hoping to tease it out by creating the issue |
|
...and a single WARC as large as 80G. |
|
Reading the garbage collection post reminded me that Spark allocates (not sure if that is the right word), ~55-60% of "storage" memory for executors. A smarter version of me would have bookmarked that Stackoverflow or Spark mailing list thread. But, I can provide a screenshot of a the Spark UI of a currently running job.
That's a job running with 30 threads, and 105G of RAM allocated: |
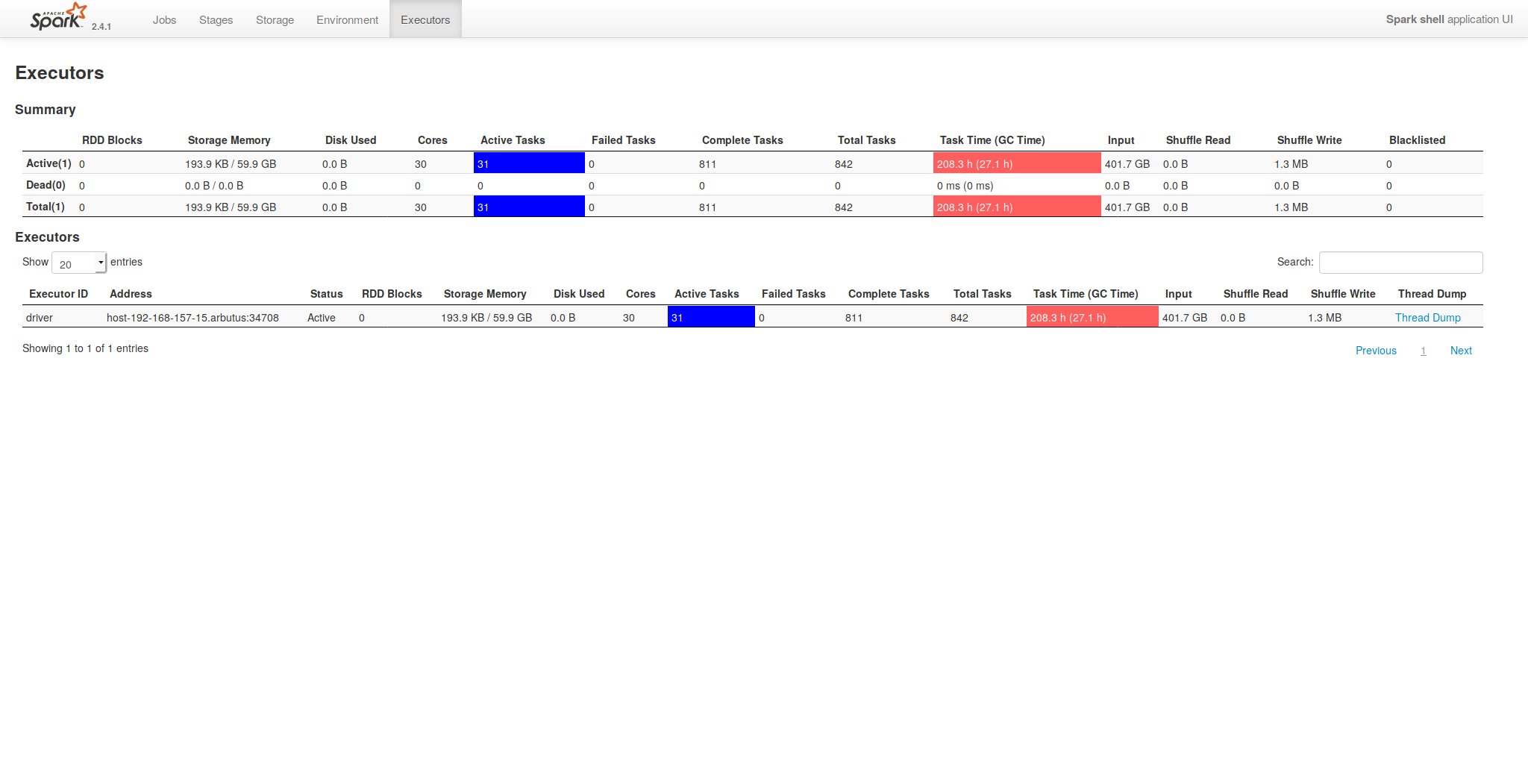
|
I'm going to start adding collection info on failed collections here:
|
|
As a sanity check, I went to the data directory and did this: 2878090679 = 2,878,090,679 ~ 2.9 GB. A bit silly to have records that big... dunno if this is the source of your errors though. |
|
So an individual record that’s almost 3GB? I wonder if we could implement a default that skips records greater than say a GB? Or lower? I can imagine users who might want to work with big files - video etc - but for the most part, and with our generic processing pipeline, we could do without. |
|
I'm not certain that record size is the issue. I've collected some data from a number of collections that fail, and succeed. Large record size doesn't appear to be the sole factor in failure or success. We have some that are well above what @lintool listed having been a part of successful jobs. I'll take some time over the coming days, or weeks PQ: Fails on
|
|
Hit a very similar error a couple times over the last few days on two different collections with Java 11 and Spark 3.0.0. I had initially thought it was a freak new error because of the new setup, but I believe this is the same error that we've all been running into for a few years now, and is definitely a blocker for 1.0.0. The common thread following the stack trace in all the errors in this issue are @lintool had previously patched the issue with lintool/warcbase@16db934, which I believe was meant to just skip over broken records, but didn't address the underlying issue that @anjackson brought up here; that we're hitting the 2G array limit size in Java. I think the best path forward then is to decide if we want to truncate payloads like Andy suggested (I'm not 100% sure we should be do that), or update the |
Describe the bug
On a number FDLP and Stanford collections, we run into this space heap space error, and it kills the Spark job. Upon investigation, this does not seem to be a problem with a large ARC/WARC or large collection. This happens on small and large collections.
To Reproduce
Steps to reproduce the behavior on
tuna:/tuna1/scratch/nruest/auk_collection_testing/10689/home/ruestn/spark-2.4.1-bin-hadoop2.7/bin/spark-shell --master local[30] --driver-memory 105g --conf spark.network.timeout=10000000 --conf spark.executor.heartbeatInterval=600s --conf spark.driver.maxResultSize=4g --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.shuffle.compress=true --conf spark.rdd.compress=true -Djava.io.tmpdir=/tuna1/scratch/nruest/tmp --jars /home/ruestn/aut/target/aut-0.17.1-SNAPSHOT-fatjar.jar -i /tuna1/scratch/nruest/auk_collection_testing/10689/133/spark_jobs/10689.scala 2>&1 | tee /tuna1/scratch/nruest/auk_collection_testing/10689/133/spark_jobs/10689.scala-test.logExpected behavior
Shouldn't hit the heap error.
Environment information
--jarsand--pagackes/home/ruestn/spark-2.4.1-bin-hadoop2.7/bin/spark-shell --master local[30] --driver-memory 105g --conf spark.network.timeout=10000000 --conf spark.executor.heartbeatInterval=600s --conf spark.driver.maxResultSize=4g --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.shuffle.compress=true --conf spark.rdd.compress=true -Djava.io.tmpdir=/tuna1/scratch/nruest/tmp --jars /home/ruestn/aut/target/aut-0.17.1-SNAPSHOT-fatjar.jar -i /tuna1/scratch/nruest/auk_collection_testing/10689/133/spark_jobs/10689.scala 2>&1 | tee /tuna1/scratch/nruest/auk_collection_testing/10689/133/spark_jobs/10689.scala-test.logAdditional context
tuna, the job runs fine./tuna1/scratch/nruest/auk_collection_testing/9635is another collection to test on