Last week, I virtually attended the Knowledge Graph Conference 2020. Originally, KGC was planned to be hosted in New York at Columbia University but, as with everything, had to go online because of the pandemic.
Before getting to the content, I wanted to talk about logistics. Kudos to Francois Scharffe and the team for putting this conference online quickly and running it so smoothly. Just thinking of all the small things – for example, as a speaker I was asked to do a dry run with the organizers and get comments back for how the presentation went on Zoom. The conference Slack workspace was booming with tons of different challenges. The organizers had a nice cadence of talk announcements while boosting conversation by pushing the Q/A session onto Slack. This meant that the conversations could continue beyond each individual session. At the meta level, they managed to get the intensity of a conference online through the amount of effort in curating those Slack channels along with the rapid fire pace of the talks over the two main track days. Personally, I somehow found this more tiring than F2F because somehow Zoom presentations require full focus to ingest. Additionally, there’s this temptation to do both the conference and your normal workday when the event is in another time zone….which… err.. I might have been guilty of. I also did have some hallway conversations on Slack but not as much as I normally would in a F2F setting.
But what’s the conference about? KGC started last year with the idea of having an application and business oriented event focused on knowledge graphs. I would summarize the aim is to bring people together to talk about knowledge graph technology in action, see the newest commercially ready tech and get a glimpse of future tech. The conference has the same flavor of Connected Data London . As a researcher, I really enjoy seeing the impact these technologies are having in a myriad of domains.
So what was I doing there? I was talking about Knowledge Graph Maintenance (slides) – how do we integrate machine learning techniques and the work of people to not only create but maintain knowledge graphs. Here’s my talk summarized in one picture:
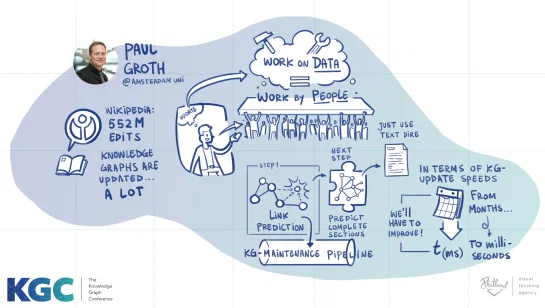
My goal is to get organizations who are adopting knowledge graphs to think not only about one-of creation but think about what goes in to keeping that knowledge up-to-date. I also wanted to give a sketch of the current research we’ve been doing in this direction.
There was a lot of content at this event (which will be available online) so I’ll just call out three things I took away from it.
Human Understandable Data
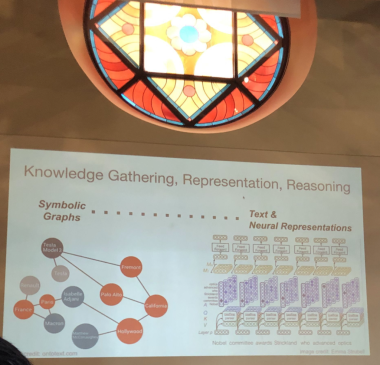
One of the themes that kept coming up was the use of knowledge graphs to help the data in an organization match the conceptualizations that are used within businesses. Sure we can do this by saying we need to build an ontology or logical model or a semantic dictionary but the fundamental point that was highlighted again and again is that this data-to-business bridge was the purpose of building many knowledge graphs. It was kind of summed up in the following two slides from Michael Grove:


This also came through in Ora Lassila’s talk (now at Amazon Neptune) as well as the the tutorial I attended by Juan Sequeda about building Enterprise Knowledge Graphs from Relational Databases. Juan ran through a litany of mapping patterns all trying to bridge from data stored for specific applications to human understandable data. I’m looking forward to seeing this tutorial material available.
The Knowledge Scientist
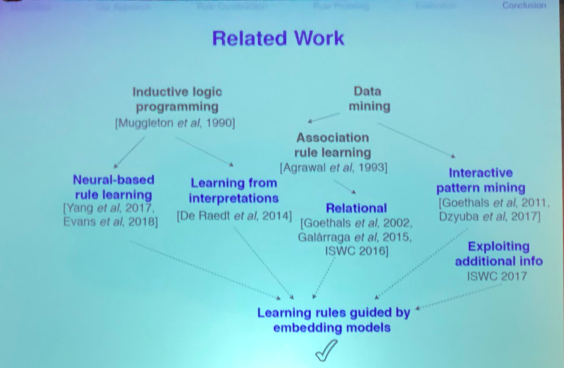
Given the need to bridge the gap between application data and business level goals, new kinds of knowledge engineering and tools to facilitate that we’re also of interest. Why aren’t existing approaches enough? I think the assumption is that there’s a ton of data that people doing this activity need to deal with. Both Juan and I discussed the need to recognize these sorts of people – which we call a Knowledge Scientist– and it seemed to resonate or at least the premise behind the term did.
An excellent example of supporting this sort of tools to support knowledge engineering was by Rafael Gonçalves on how Pinterest used WebProtege to update and manage their taxonomy (paper):

Likewise, Bryon Jacob discussed about how the first step to getting to a knowledge graph was through the better cataloging of data within the organization. It reminds me of the lesson we learned from linked data – that before we can have knowledge we need to index and catalog the underlying data. Also, I can never overlook a talk that gives a shoutout to PROV and the need for lineage and provenance 🙂 .
Knowledge Graphs as Data Assets
I really enjoyed seeing all the various kinds of application areas using knowledge graphs. There were early domain adopters for example in drug discovery and scholarly data that have pushed further in using this technology:
But also new domains like personal health (e.g. deck from Jim Hendler).
The two I liked the most were on law and real estate. David Kamien fromMind Alliance talked about how knowledge graphs in combination with NLP can specifically help law firms for example by automatically suggesting new business development opportunities by analyzing court dockets.
Ron Bekkerman‘s talk on the real estate knowledge graph that they’ve constructed at Cherre was the most eye opening to me. Technically, it was cool in that are applying geometric deep learning to perform entity resolution to build a massive graph of real estate. I had been at another academic workshop on this only a ~2 weeks prior. But from a business sense, their fundamental asset is that the cleaned data in the form of a knowledge graph. It’s not just data but reliable connected data. Really one to watch.
To wrap-up, the intellectual history of knowledge graphs is long (ee John Sowa’s slides and knowledgegraph.today) but I think it’s nice to see that we are at stage where this technology is being deployed at scale in practice, which brings additional research challenges for folks like me.
Part of the Knowledge Graph of the Knowledge Graph Conference:

Random Notes
- A nice article on the conference in ZDNet.
- Job Amazon – Knowledge Graph Software Development manager
- Awesome Semantic Web
- Interesting tagger – annif.org
- Tutorial: Building a Knowledge Graph from Schema.org annotations
- Import / Export RDF from neo4
- kgbase.com – no code knowledge graphs.
 Good job!
Good job!




 It was quite good, I hope they put the slides up somewhere. The key notion for me is this idea of instance optimality: by using machine learning we can tailor performance to specific users and applications whereas in the past this was not cost effective because the need for programmer effort. They suggested 4 ways to create instance optimized algorithms and data structures:
It was quite good, I hope they put the slides up somewhere. The key notion for me is this idea of instance optimality: by using machine learning we can tailor performance to specific users and applications whereas in the past this was not cost effective because the need for programmer effort. They suggested 4 ways to create instance optimized algorithms and data structures: