The Archives Unleashed Toolkit

The Archives Unleashed Toolkit is an open-source platform for analyzing web archives built on Apache Spark, which provides powerful tools for analytics and data processing. This toolkit is part of the Archives Unleashed Project.
The following two articles give an overview of the project:
- Jimmy Lin, Ian Milligan, Jeremy Wiebe, and Alice Zhou. Warcbase: Scalable Analytics Infrastructure for Exploring Web Archives. ACM Journal on Computing and Cultural Heritage, 10(4), Article 22, 2017.
- Nick Ruest, Jimmy Lin, Ian Milligan, Samantha Fritz. The Archives Unleashed Project: Technology, Process, and Community to Improve Scholarly Access to Web Archives. 2020.
Dependencies
Java
The Archives Unleashed Toolkit requires Java 8.
For macOS: You can find information on Java here, or install with homebrew and then:
brew cask install java8On Debian based system you can install Java using apt:
apt install openjdk-8-jdkBefore spark-shell can launch, JAVA_HOME must be set. If you receive an error that JAVA_HOME is not set, you need to point it to where Java is installed. On Linux, this might be export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 or on macOS it might be export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_74.jdk/Contents/Home.
Python
If you would like to use the Archives Unleashed Toolkit with PySpark and Jupyter Notebooks, you'll need to have a modern version of Python installed. We recommend using the Anaconda Distribution. This should install Jupyter Notebook, as well as the PySpark bindings. If it doesn't, you can install either with conda install or pip install.
Apache Spark
Download and unzip Apache Spark to a location of your choice.
curl -L "https://archive.apache.org/dist/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz" > spark-2.4.4-bin-hadoop2.7.tgz
tar -xvf spark-2.4.4-bin-hadoop2.7.tgzGetting Started
Building Locally
Clone the repo:
$ git clone http://github.com/archivesunleashed/aut.gitYou can then build The Archives Unleashed Toolkit.
$ mvn clean installArchives Unleashed Toolkit with Spark Shell
There are a two options for loading the Archives Unleashed Toolkit. The advantages and disadvantages of using either option are going to depend on your setup (single machine vs cluster):
$ spark-shell --help
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.As a package
Release version:
$ spark-shell --packages "io.archivesunleashed:aut:0.50.0" --repositories "https://jitpack.io"HEAD (built locally):
$ spark-shell --packages "io.archivesunleashed:aut:0.18.2-SNAPSHOT" --repositories "https://jitpack.io"With an UberJar
Release version:
$ spark-shell --jars /path/to/aut-0.50.0-fatjar.jarHEAD (built locally):
$ spark-shell --jars /path/to/aut/target/aut-0.18.2-SNAPSHOT-fatjar.jarArchives Unleashed Toolkit with PySpark
To run PySpark with the Archives Unleashed Toolkit loaded, you will need to provide PySpark with the Java/Scala package, and the Python bindings. The Java/Scala packages can be provided with --packages or --jars as described above. The Python bindings can be downloaded, or built locally (the zip file will be found in the target directory.
In each of the examples below, /path/to/python is listed. If you are unsure where your Python is, it can be found with which python.
As a package
Release version:
$ export PYSPARK_PYTHON=/path/to/python; export PYSPARK_DRIVER_PYTHON=/path/to/python; /path/to/spark/bin/pyspark --py-files aut-0.50.0.zip --packages "io.archivesunleashed:aut:0.50.0" --repositories "https://jitpack.io"HEAD (built locally):
$ export PYSPARK_PYTHON=/path/to/python; export PYSPARK_DRIVER_PYTHON=/path/to/python; /path/to/spark/bin/pyspark --py-files /home/nruest/Projects/au/aut/target/aut.zip --packages "io.archivesunleashed:aut:0.18.2-SNAPSHOT" --repositories "https://jitpack.io"With an UberJar
Release version:
$ export PYSPARK_PYTHON=/path/to/python; export PYSPARK_DRIVER_PYTHON=/path/to/python; /path/to/spark/bin/pyspark --py-files aut-0.50.0.zip --jars /path/to/aut-0.50.0-fatjar.jarHEAD (built locally):
$ export PYSPARK_PYTHON=/path/to/python; export PYSPARK_DRIVER_PYTHON=/path/to/python; /path/to/spark/bin/pyspark --py-files /home/nruest/Projects/au/aut/target/aut.zip --jars /path/to/aut-0.18.2-SNAPSHOT-fatjar.jarArchives Unleashed Toolkit with Jupyter
To run a Jupyter Notebook with the Archives Unleashed Toolkit loaded, you will need to provide PySpark the Java/Scala package, and the Python bindings. The Java/Scala packages can be provided with --packages or --jars as described above. The Python bindings can be downloaded, or built locally (the zip file will be found in the target directory.
As a package
Release version:
$ export PYSPARK_DRIVER_PYTHON=jupyter; export PYSPARK_DRIVER_PYTHON_OPTS=notebook; /path/to/spark/bin/pyspark --py-files aut-0.50.0.zip --packages "io.archivesunleashed:aut:0.50.0" --repositories "https://jitpack.io"HEAD (built locally):
$ export PYSPARK_DRIVER_PYTHON=jupyter; export PYSPARK_DRIVER_PYTHON_OPTS=notebook; /path/to/spark/bin/pyspark --py-files /home/nruest/Projects/au/aut/target/aut.zip --packages "io.archivesunleashed:aut:0.18.2-SNAPSHOT" --repositories "https://jitpack.io"With an UberJar
Release version:
$ export PYSPARK_DRIVER_PYTHON=jupyter; export PYSPARK_DRIVER_PYTHON_OPTS=notebook; /path/to/spark/bin/pyspark --py-files aut-0.50.0.zip --jars /path/to/aut-0.50.0-fatjar.jarHEAD (built locally):
$ export PYSPARK_DRIVER_PYTHON=jupyter; export PYSPARK_DRIVER_PYTHON_OPTS=notebook; /path/to/spark/bin/pyspark --py-files /home/nruest/Projects/au/aut/target/aut.zip --jars /path/to/aut-0.18.2-SNAPSHOT-fatjar.jarA Jupyter Notebook should automatically load in your browser at http://localhost:8888. You may be asked for a token upon first launch, which just offers a bit of security. The token is available in the load screen and will look something like this:
[I 19:18:30.893 NotebookApp] Writing notebook server cookie secret to /run/user/1001/jupyter/notebook_cookie_secret
[I 19:18:31.111 NotebookApp] JupyterLab extension loaded from /home/nruest/bin/anaconda3/lib/python3.7/site-packages/jupyterlab
[I 19:18:31.111 NotebookApp] JupyterLab application directory is /home/nruest/bin/anaconda3/share/jupyter/lab
[I 19:18:31.112 NotebookApp] Serving notebooks from local directory: /home/nruest/Projects/au/aut
[I 19:18:31.112 NotebookApp] The Jupyter Notebook is running at:
[I 19:18:31.112 NotebookApp] http://localhost:8888/?token=87e7a47c5a015cb2b846c368722ec05c1100988fd9dcfe04
[I 19:18:31.112 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:18:31.140 NotebookApp]
To access the notebook, open this file in a browser:
file:///run/user/1001/jupyter/nbserver-9702-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=87e7a47c5a015cb2b846c368722ec05c1100988fd9dcfe04
Create a new notebook by clicking “New” (near the top right of the Jupyter homepage) and select “Python 3” from the drop down list.
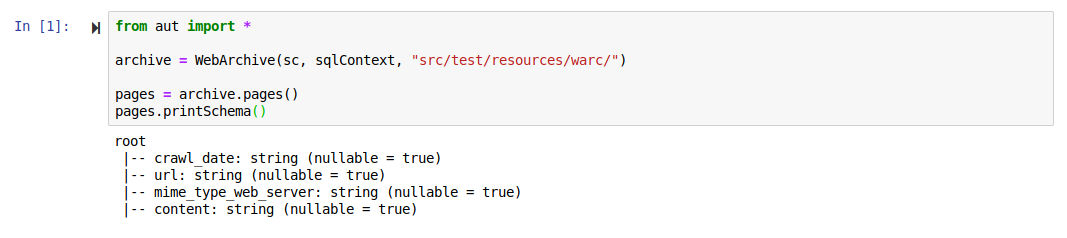
The notebook will open in a new window. In the first cell enter:
from aut import *
archive = WebArchive(sc, sqlContext, "src/test/resources/warc/")
webpages = archive.webpages()
webpages.printSchema()Then hit Shift+Enter, or press the play button.
If you receive no errors, and see the following, you are ready to begin working with your web archives!
Documentation! Or, what can I do?
Once built or downloaded, you can follow the basic set of recipes and tutorials here.
License
Licensed under the Apache License, Version 2.0.
Acknowledgments
This work is primarily supported by the Andrew W. Mellon Foundation. Other financial and in-kind support comes from the Social Sciences and Humanities Research Council, Compute Canada, the Ontario Ministry of Research, Innovation, and Science, York University Libraries, Start Smart Labs, and the Faculty of Arts and David R. Cheriton School of Computer Science at the University of Waterloo.
Any opinions, findings, and conclusions or recommendations expressed are those of the researchers and do not necessarily reflect the views of the sponsors.