Join GitHub today
GitHub is home to over 31 million developers working together to host and review code, manage projects, and build software together.
Sign up[REVIEW]: dlmmc: Dynamical linear model regression for atmospheric time-series analysis #1157
Comments
 whedon
assigned
danielskatz
whedon
assigned
danielskatz
Jan 7, 2019
whedon
added
the
review
label
Jan 7, 2019
whedon
referenced this issue
Jan 7, 2019
Closed
[PRE REVIEW]: dlmmc: Dynamical linear model regression for atmospheric time-series analysis #1140
This comment has been minimized.
This comment has been minimized.
|
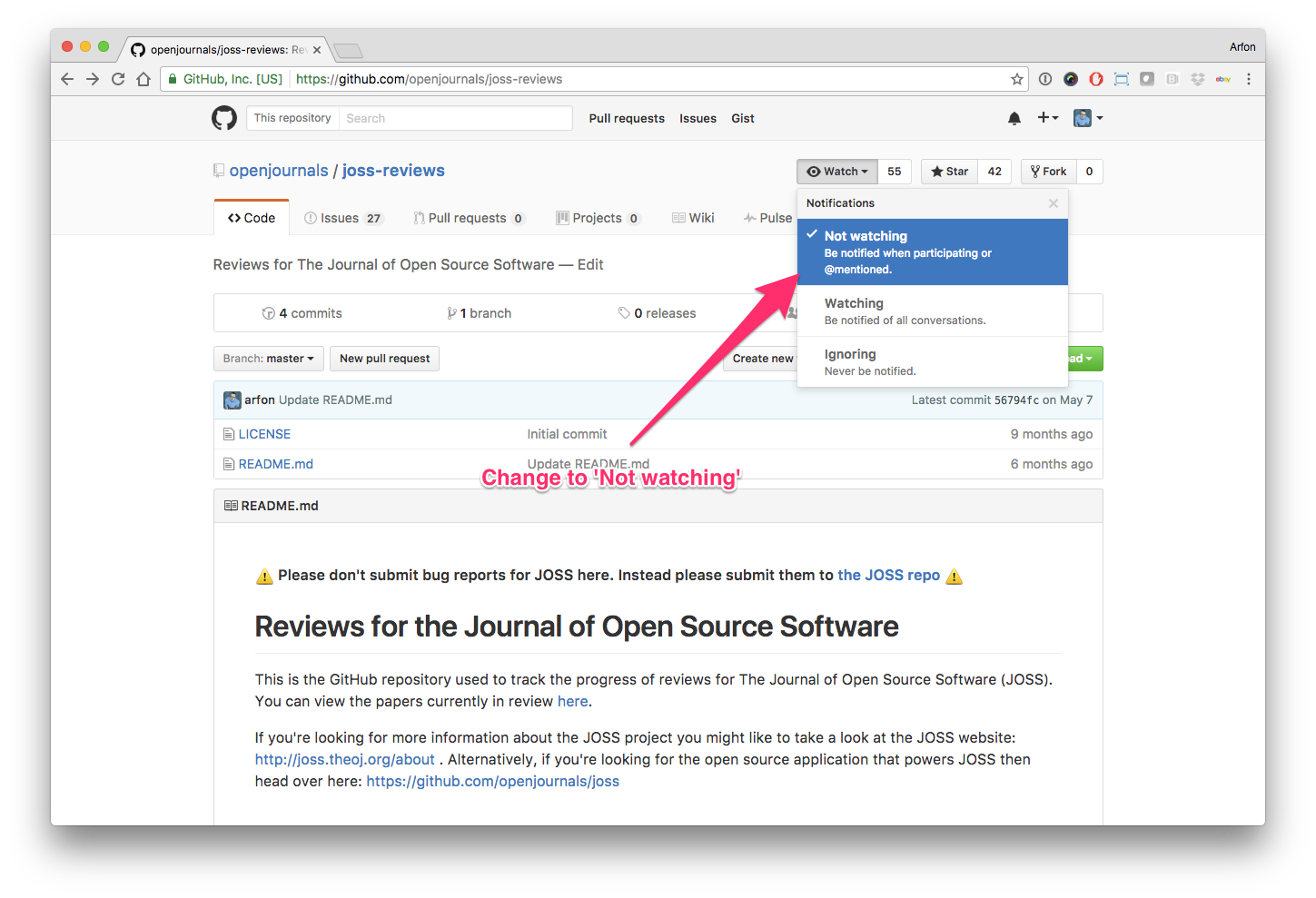
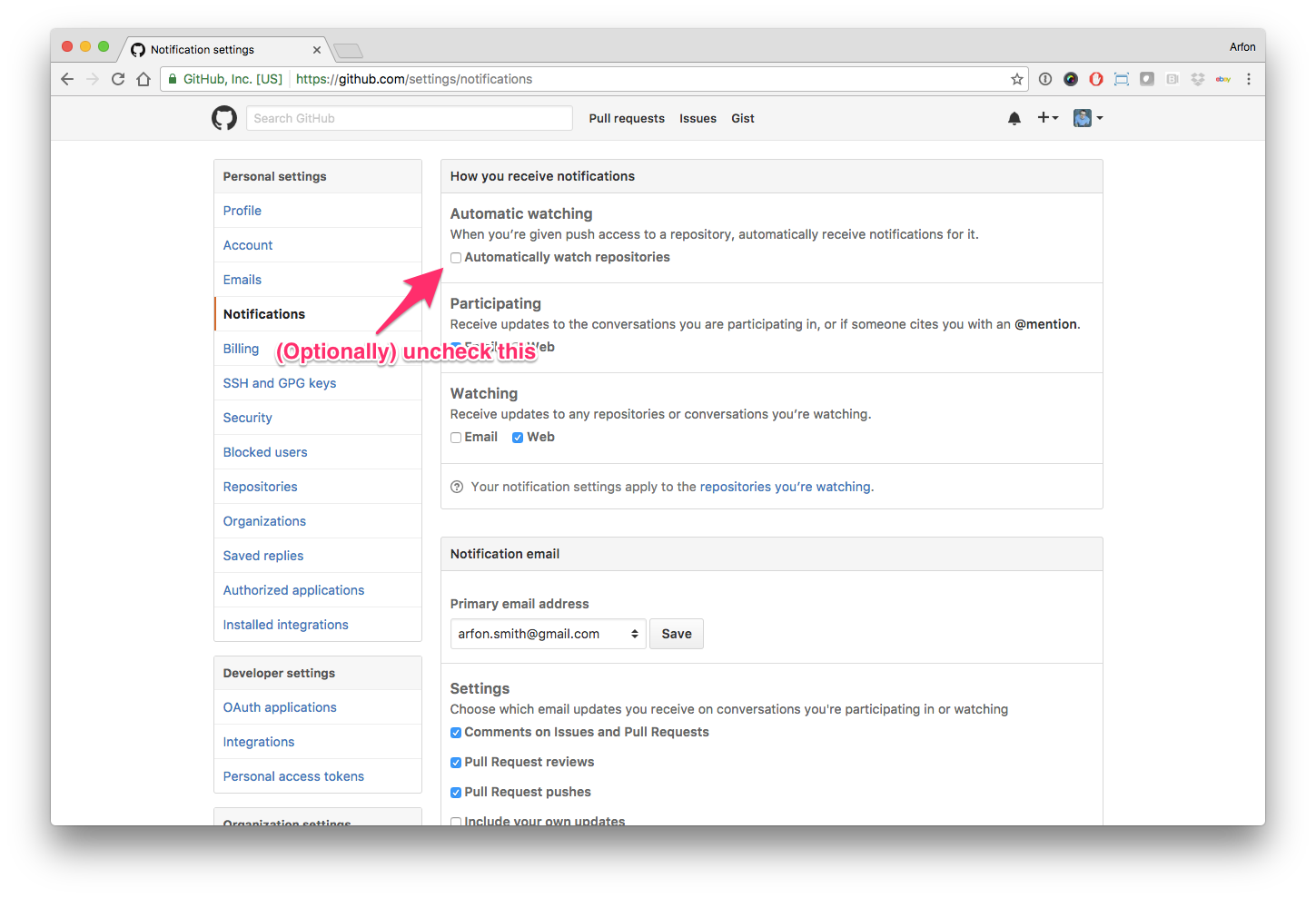
Hello human, I'm @whedon, a robot that can help you with some common editorial tasks. @Chilipp, it looks like you're currently assigned as the reviewer for this paper If you haven't already, you should seriously consider unsubscribing from GitHub notifications for this (https://github.com/openjournals/joss-reviews) repository. As a reviewer, you're probably currently watching this repository which means for GitHub's default behaviour you will receive notifications (emails) for all reviews To fix this do the following two things:
For a list of things I can do to help you, just type: |
This comment has been minimized.
This comment has been minimized.
|
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
@Chilipp, @taqtiqa-mark - thanks for agreeing to review. (Note that @Chilipp will not be able to start for a week.) If you have any questions, please ask. Otherwise, I'll expect that you will work through the checklists above and raise issues as you find items you cannot check off. |
 danielskatz
assigned
taqtiqa-mark and
Chilipp
danielskatz
assigned
taqtiqa-mark and
Chilipp
Jan 17, 2019
This comment has been minimized.
This comment has been minimized.
|
|
This comment has been minimized.
This comment has been minimized.
|
Yes, @danielskatz, I will start tomorrow. My apologies for the delay |
This comment has been minimized.
This comment has been minimized.
|
|
This comment has been minimized.
This comment has been minimized.
|
Hello @justinalsing! I am so far done with my first look into your software and I would like to have your feedback on some of the following points: General checks
Functionality
Documentation
Software paper
|
This comment has been minimized.
This comment has been minimized.
|
|
This comment has been minimized.
This comment has been minimized.
justinalsing
commented
Jan 30, 2019
|
Hi @CHILLIP, @danielskatz, @taqtiqa-mark Thanks for all the feedback and sorry for the delay. Let me try to address your points: Version thanks for pointing this out! I’ve just made a release, v1.0 Installation I saw you had problems installing with pip. The dependency that typically causes problems (as in your case) is pyston, since it needs to play nicely with the C++ compilers on your machine. For some it has worked with pip, for others it seems to work with conda but not pip. I’ve added a note to the README that says you can use “conda install (recommended) or pip” and another note, “Note: conda seems to be more stable for getting pystan to work than pip - if you installed with pip and compiling the stan models throws errors, try again with with conda.” Do you have any other suggestions for making the install instructions more solid? I’ve also added a point in the README that prior knowledge of python/jupyter is needed to be able to fully follow the tutorial, as suggested. Agree this was a good idea. Statement of need yes, I intend that the HMC-Kalman filtering framework can be used to expand the suite of models beyond those initially provided. Essentially the space of DLM models are characterized by a few model matrices; more-or-less all that needs modifying in the stan model code to implement a new one is to replace the model matrices and add any additional hyper-parameters. I’ve now provided a CONTRIBUTING file as you suggested giving details of how to contribute extended models to the suite. It does assume familiarity with stan, which I think is needed to contribute meaningfully. I’d be happy to give further details here if you feel they are needed and am very open to suggestions on how to improve this. Automated tests In my mind the tutorial also serves this purpose: if the models compile and the tutorial runs through without error, you’re in good shape. I’ve added a note to the README that the tutorial also serves this purpose. However, if you feel additional tests are required I am open to suggestions.. Community guidelines see above re added CONTRIBUTING file. References I’ve updated the references in the model_descriptions.pdf as suggested (thanks for pointing those out) I hope this addresses your points and look forward to hearing your further thoughts Thanks again! |
This comment has been minimized.
This comment has been minimized.
|
My apologies for the delay. It took a while to find my first notes. which follow: I've had a quick look at the model PDF and some of the repository and can say, while its fresh in my mind: The use-case appears to be reasonably well motivated - implementing a known/published model, and a non-trivial software stack (e.g. parallel libraries). My working assumption is the question of originality is out-of-scope - it suffices that the library implements a model already published. Consequently, while non-linear AR/(G)ARCH models are wide spread, I haven't investigated the question of whether this improves on them. However I would suggest that data sets used thought to have those properties from the R-project, would be used in the test suite. Given the JOSS is software focused I'm placing all emphasis on the software engineering aspects, and almost non on the contribution to domain knowledge. That non-trivial software stack nature suggests weight be given to the following observations:
I'll update this with links to the issues opened against the upstream project, as I open them. @danielskatz, for me blocking issues are:
|
This comment has been minimized.
This comment has been minimized.
|
Thanks @taqtiqa-mark - these details are very helpful. In JOSS, we don't really have results like
We just say what's needed to be done, and then let the author decide to do this or not. In other words, we keep going until the submission is acceptable or we decide that it cannot be made so. |
This comment has been minimized.
This comment has been minimized.
justinalsing
commented
Feb 1, 2019
|
Hi @taqtiqa-mark , Thanks for your feedback. I think it would help it I reiterate/clarify the scope of this code. The code is a suite of statistical models, written in stan, than can then be ran on user’s data using the pystan interface (provided by the stan team). Along with the models, I provide a tutorial covering how to run the stan models using pystan — this is really to ease the way for users who are not familiar with pystan. For users who want to run many DLMs quickly but are not used to setting up MPI runs with python, I also provide a template for how to run models in parallel this way. The tutorial and MPI-run template are really examples of how to use the code to help users get up and running quickly, rather than central to the package. That is why, for example, I do not attempt to give openmpi install instructions that will work robustly for everyone — as you point out that is a difficult thing to do in practice. Since the package is a suite of models implemented in a probabilistic-programming language, the model code “in of itself” does not have any “functionality” to be documented, ie., the model codes in There is a question of whether a suite of stan models constitutes a valid open source project. I believe it does for the following reasons: I hope this focuses the discussion on what I should do to make this code ready for public consumption. @taqtiqa-mark and @CHILLIP, you both raised automated tests and more robust install instructions. If you have some concrete ideas/specifications for what you think is needed here I’d greatly appreciate it. The other related point you raised @taqtiqa-mark is validation. Validation of Bayesian codes is non-trivial, requiring either comparison to a known analytical posterior (hard in this case), comparing to another code, or running on a large ensemble of mock data vectors and looking at the statistical properties of the results (expensive). If you really feel this is a requirement I’d love to hear what you think would be most worthwhile here. |
This comment has been minimized.
This comment has been minimized.
|
I've amended my comment o remove that observation. @justinalsing makes the following observation:
My assumption is that this question has been resolved in the affirmative by the (sub-)editor(s) - otherwise this would not have progressed to the review stage. If incorrect, are there JOSS guidelines to on what is a "valid open source project" (for the purposes of JOSS) to guide reviewers to address this issue in a way that results in consistent outcomes? I'll address @justinalsing response separately - by editing my comments above to add links to issue in his repository - to prevent this thread from becoming spaghetti. |
This comment has been minimized.
This comment has been minimized.
Yes, this is correct. |
This comment has been minimized.
This comment has been minimized.
|
Also, @taqtiqa-mark - I think that rather than editing comments to address responses, it's better to just write a new comment, and, as you've said, to open issues in the source repository with links to them here. And so, to get an up-to-date status, can you (and also @Chilipp) please add new comments below that tell us what your current concerns are (linking to issues as needed)? |
referenced
this issue
in justinalsing/dlmmc
Feb 7, 2019
This comment has been minimized.
This comment has been minimized.
|
thanks @justinalsing for your detailed responses to my comments and the ones from @taqtiqa-mark ! I especially appreciate your work on the contribution guidelines. There are still some open points and I would like to outsource them to other issues in your repository:
If you work on these issues, please directly comment in the issues in your repository as this is also recommended in the review process guidelines above
|
This comment has been minimized.
This comment has been minimized.
|
Re: automated tests - The JOSS requirement is just "Are there automated tests or manual steps described so that the function of the software can be verified?" While automated tests are generally better for the software, manual steps are sufficient for JOSS acceptance. Specifically, adding good automated tests can be a longer-term activity than JOSS acceptance. |
whedon commentedJan 7, 2019
•
edited by Chilipp
Submitting author: @justinalsing (Justin Alsing)
Repository: https://github.com/justinalsing/dlmmc
Version: v1.0.0
Editor: @danielskatz
Reviewer: @Chilipp, @taqtiqa-mark
Archive: Pending
Status
Status badge code:
Reviewers and authors:
Please avoid lengthy details of difficulties in the review thread. Instead, please create a new issue in the target repository and link to those issues (especially acceptance-blockers) in the review thread below. (For completists: if the target issue tracker is also on GitHub, linking the review thread in the issue or vice versa will create corresponding breadcrumb trails in the link target.)
Reviewer instructions & questions
@Chilipp & @taqtiqa-mark, please carry out your review in this issue by updating the checklist below. If you cannot edit the checklist please:
The reviewer guidelines are available here: https://joss.theoj.org/about#reviewer_guidelines. Any questions/concerns please let @danielskatz know.
Review checklist for @Chilipp
Conflict of interest
Code of Conduct
General checks
Functionality
Documentation
Software paper
paper.mdfile include a list of authors with their affiliations?Review checklist for @taqtiqa-mark
Conflict of interest
Code of Conduct
General checks
Functionality
Documentation
Software paper
paper.mdfile include a list of authors with their affiliations?