Join GitHub today
GitHub is home to over 31 million developers working together to host and review code, manage projects, and build software together.
Sign upNew translator for www.springer.com #1440
Conversation
psisquared2
added some commits
Oct 7, 2017
adam3smith
requested changes
Oct 15, 2017
|
Thanks! |
| //Try to find additional information | ||
| if (!item.publisher) { | ||
| publisher = ZU.xpathText(doc, '//dd[@itemprop="publisher"]/span'); | ||
| item.publisher = publisher; |
This comment has been minimized.
This comment has been minimized.
adam3smith
Oct 15, 2017
Collaborator
I'd try to split this into publisher and place. Since presumably the first part is always "Springer-Verlag" you could do something like:
if (item.publisher && item.publisher.search(/^Springer-Verlag\s.+/)!=-1) {
var publisherInfo = item.publisher.match(/^(Springer-Verlag)\s(.+)/);
item.publisher = publisherInfo[1]
item.place = publisherInfo[2]
}
| //The abstract note is shortened in the <meta> field; try to load | ||
| //the full abstract note | ||
| long_abstractNote = ZU.xpath(doc, '//div[@class="product-about"]//div[@class="springer-html"]'); | ||
| long_abstractNote = long_abstractNote[0].textContent.trim(); |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
Thank you for the feedback. I have addressed the issues you mentioned, added support for multiples and also improved a few minor quirks on the way. Please let me know if you see further issues or room for improvement. One question: In case the publisher is officially listed as "Springer-Verlag Berlin Heidelberg" (which happens a lot), do we want to split this into publisher="Springer-Verlag" and place="Berlin Heidelberg"? Seems a little weird to have two locations in "place", but it's probably the best we can do. The only other option I see is to revert to not filling the "place" field at all. |
psisquared2
added some commits
Oct 23, 2017
 zuphilip
added
the
New Translator
label
zuphilip
added
the
New Translator
label
Nov 12, 2017
zuphilip
reviewed
Jan 3, 2018
| "maxVersion": "", | ||
| "priority": 100, | ||
| "inRepository": true, | ||
| "translatorType": 12, |
This comment has been minimized.
This comment has been minimized.
| "priority": 100, | ||
| "inRepository": true, | ||
| "translatorType": 12, | ||
| "browserSupport": "gcsbv", |
This comment has been minimized.
This comment has been minimized.
| /* | ||
| ***** BEGIN LICENSE BLOCK ***** | ||
| Copyright © 2017 YourName |
This comment has been minimized.
This comment has been minimized.
| // test if any relevant <meta> information is available | ||
| if(ZU.xpathText(doc, '//meta[@property="og:title"]/@content')) return "book"; | ||
| //test for relevant search entries | ||
| case "search": return getSearchResults(doc, true) ? "multiple" : false; |
This comment has been minimized.
This comment has been minimized.
zuphilip
Jan 3, 2018
Collaborator
Write this on two lines and then move the comment from above to corresponding line, i.e.
case "search":
// test for relevant search entries
return getSearchResults(doc, true) ? "multiple" : false;| var item_type = search_entries[i].getAttribute("class"); | ||
| //test if we actually have a usable result | ||
| if (!item_type || item_type.search(/result-item result-item-\d+ result-type-book.*/) == -1) continue; | ||
| var title_link = ZU.xpath(search_entries[i], "h4/a"); |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
psisquared2
Jan 13, 2018
Author
Contributor
This html looks e.g. like
<div class="result-item result-item-3 result-type-book">
<some stuff>
<h4>
<a href="/us/book/978-981-10-0217-5">National Test</a>
</h4>and the xpath looks for a top level h4 with an a below. Would you suggest a different xpath for that?
| switch (detection_type) { | ||
| case "book": scrapeBook(doc, url); | ||
| case "multiple": { | ||
| if (!getSearchResults(doc, true)) return; |
This comment has been minimized.
This comment has been minimized.
| for (var i=0; i<search_entries.length; i++) { | ||
| var item_type = search_entries[i].getAttribute("class"); | ||
| //test if we actually have a usable result | ||
| if (!item_type || item_type.search(/result-item result-item-\d+ result-type-book.*/) == -1) continue; |
This comment has been minimized.
This comment has been minimized.
zuphilip
Jan 3, 2018
Collaborator
This looks fragile, because there is no order for the classes of a node. I would suggest something like
item_type.includes('result-item') && item_type.includes('result-item-') && item_type.includes('result-type-book')Not tested. Or maybe just part of what is important...
| //forward compatibility: check if the embedded metadata translator | ||
| //has found a creator (i.e. relevant metadata) | ||
| if (item.creators.length > 0) { | ||
| item.complete; return; |
This comment has been minimized.
This comment has been minimized.
zuphilip
Jan 3, 2018
Collaborator
Why can we end here if one creator is found?
Can we do more individual tests that certain parts are possibly missing?
This comment has been minimized.
This comment has been minimized.
psisquared2
Jan 13, 2018
Author
Contributor
My idea was that if Springer ever changes their website and decides to include more metadata, my translator would fall back to the embedded metadata translator.
| //Step 1: decompose item.title into the "title" field from the bibliography | ||
| //and the (potentially abbreviated) subtitle | ||
| var titlesXpath = ZU.xpath(doc, '//div[@class="product-bibliographic"]/dl/dd/div/div/dl/dd'); | ||
| var titleCand = null; |
This comment has been minimized.
This comment has been minimized.
zuphilip
Jan 3, 2018
Collaborator
I don't think this title e.g. Theoretical Physics 7 - Quantum Mechanics - Methods and | Wolfgang Nolting | Springer is a good text to extract any information from. How about the information at the bottom, e.g.
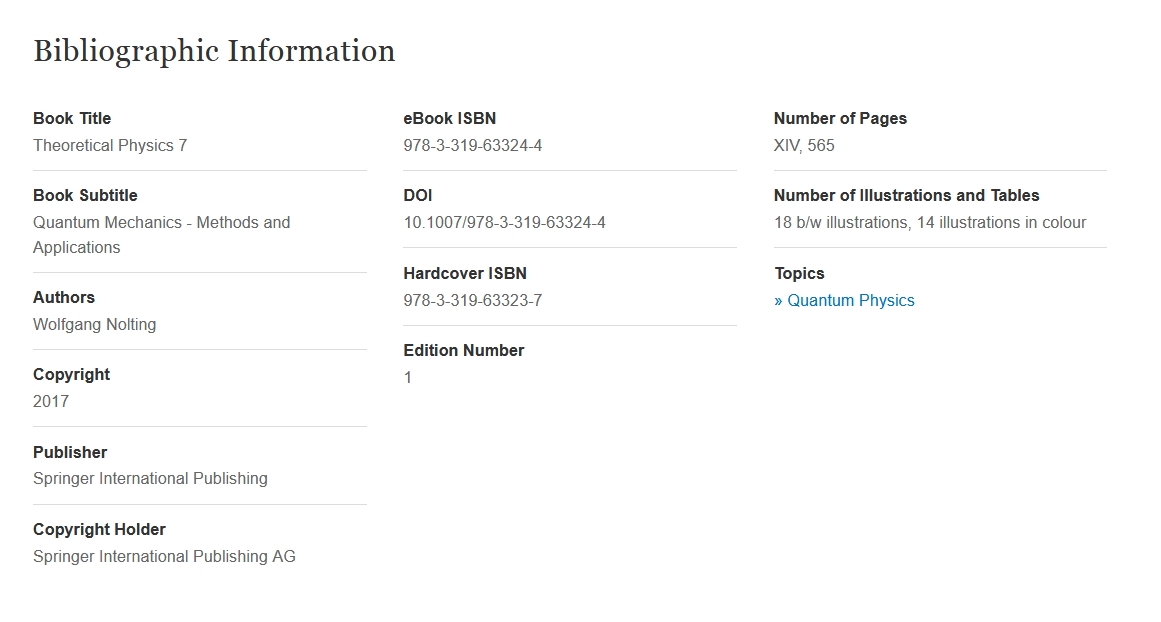
? One should also check for the remaining lines here...
This comment has been minimized.
This comment has been minimized.
psisquared2
Jan 13, 2018
Author
Contributor
The problem is that the structure of this table is not consistent across different books, and only the author, publisher, and ISBN can be accessed in a stable way. I decided to first parse the information from the metadata because that is guaranteed to be correct, but might be abbreviated. In a second step I search the information at the bottom for the complete title, subtitle, and author and check these against the data I have from step 1. That is where the function shortenedStringTest from above is used. I found that this is the most stable thing one can do.
| if (origStr.length < 10) | ||
| return (origStr == newStr.substring(0, origStr.length)); | ||
| else | ||
| return (origStr.substring(0,9) == newStr.substring(0,9)); |
This comment has been minimized.
This comment has been minimized.
zuphilip
Jan 3, 2018
Collaborator
I don't understand this function. The 9 looks like an arbitrary number here. Can you clarify?
This comment has been minimized.
This comment has been minimized.
psisquared2
Jan 13, 2018
Author
Contributor
This function is a plausibility check if one string is a shortened version of a different one, e.g. Quantum Mechanics - Methods and ... and Quantum Mechanics - Methods and Applications. It essentially compares the first 10 characters, or less if the string is shorter. See below why this is needed. One could, alternatively, check the first half of both strings; checking the full string fails in some cases where a "..." appears in the shortened string.
This comment has been minimized.
This comment has been minimized.
|
@zuphilip leaving this for you to review |
This comment has been minimized.
This comment has been minimized.
|
@adam3smith I don't think I can a review the next two weeks, sorry... |
This comment has been minimized.
This comment has been minimized.
|
@psisquared2: I simplified several things and updated the translator and pushed directly to your fork. Please have a look at the changes. This would be fine for me now to merge. |
This comment has been minimized.
This comment has been minimized.
|
@zuphilip Thank you for the improvements. The changes look fine. However, the tests failed on my machine (both Scaffold 3.3.0 release and the latest commit, which had identical outputs). I updated the tests to match Scaffold. Was there a reason for this discrepancy? |
This comment has been minimized.
This comment has been minimized.
|
Okay, thank you!
I did the test within your branch with all other files at this stage. I guess that you are using a newer EM file with the changes 7081d6b . That would explain the language info. I don't know exactly why the spaces difference, but I guess we can neglect it for the moment. |
zuphilip
merged commit 377d00c
into
zotero:master
Feb 4, 2018
1 check passed
This comment has been minimized.
This comment has been minimized.
|
Thank you very much, @psisquared2 ! (We squashed the different commits together. Thus you might need to reset your master branch in order to have a clean base again.) |
psisquared2 commentedOct 8, 2017
I have written a translator for www.springer.com (not to be confused with link.springer.com). The embedded metadata translator is only capable of extracting the title of the book on that website. I have also implemented various fallbacks to the embedded metadata translator in case the website changes.
Example website: http://www.springer.com/gb/book/9780387952697