Join GitHub today
GitHub is home to over 31 million developers working together to host and review code, manage projects, and build software together.
Sign upCreate Vice.js #1366
Conversation
owcz
reviewed
Jul 10, 2017
| } | ||
| } | ||
|
|
||
| // archives appear to 404 on load? |
This comment has been minimized.
This comment has been minimized.
owcz
Jul 10, 2017
Author
Contributor
Snapshots on every page I checked will succeed, but when later checked, they all 404. Not sure if there's a workaround or if it would be better to leave the snapshots out altogether.
This comment has been minimized.
This comment has been minimized.
zuphilip
Jul 16, 2017
Collaborator
Saving this website also fails when I try to do this in the browser. They are using a lot of JavaScript and some iframe things which seems not so friendly for saving purposes. Moreover, I haven't found a link to a "print friendly version" which sometimes exists. I suggest to skip saving snapshots here.
This comment has been minimized.
This comment has been minimized.
|
I guess that the problems you are describing are connected to some dynamic loading of the website or building the website out of some JSON together with some JavaScript calls... When coming from a multiple to a single article, then I see that some JSON data is loaded:
Actually, it looks promising to use such API calls directly and work with that JSON data rather than scrape from the page directly. In some the examples it is enough to add |
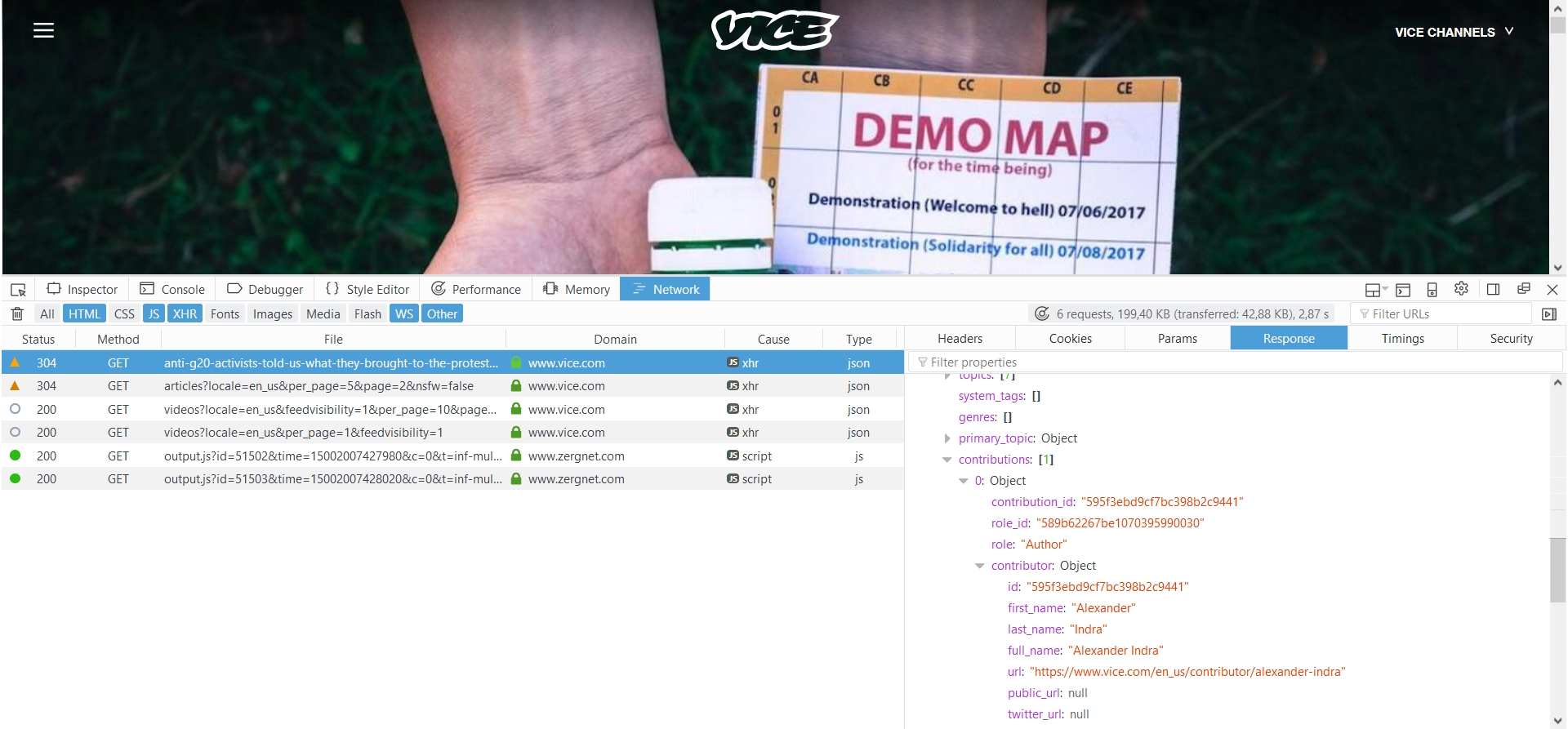
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
The news site on vice uses the WordPress API, i.e. e.g. https://news.vice.com/wp-json/wp/v2/posts/24702 |
This comment has been minimized.
This comment has been minimized.
|
Is this ready for review or are you still tweaking this? |
This comment has been minimized.
This comment has been minimized.
|
Still tweaking, thanks |
 zuphilip
added
the
New Translator
label
zuphilip
added
the
New Translator
label
Nov 12, 2017
zuphilip
added
the
waiting
label
Jan 1, 2018
This comment has been minimized.
This comment has been minimized.
|
okay, ready for review
|
zuphilip
removed
the
waiting
label
Jul 10, 2018
| "translatorID": "131310dc-854c-4629-acad-521319ab9f19", | ||
| "label": "Vice", | ||
| "creator": "czar", | ||
| "target": "^https?://((www|broadly|creators|i-d|amuse-i-d|impact|motherboard|munchies|news|noisey|sports|thump|tonic|waypoint)\\.)?vice\\.com", |
This comment has been minimized.
This comment has been minimized.
adam3smith
Jul 26, 2018
Collaborator
I'd be OK with the simpler ^https://(.+?\\.)vice\\.com unless you need to specifically exclude certain subdomains
|
|
||
| function detectWeb(doc, url) { | ||
| if (/\/(article|story)\//.test(url)) { | ||
| return "blogPost"; |
This comment has been minimized.
This comment has been minimized.
adam3smith
Jul 26, 2018
Collaborator
I would have thought of Vice as an online magazine, not as a series of blogposts -- not going to insist, but consider switching this.
To wits: Wikipedia has Vice as a magazine and it appears to have a ISSN
This comment has been minimized.
This comment has been minimized.
owcz
Jul 28, 2018
Author
Contributor
I could see potentially adding it for the base vice.com even though I don't know its overlap with the print circulation
But I'd consider all of its many subdomains to be more blog- than magazine-like in nature
| function detectWeb(doc, url) { | ||
| if (/\/(article|story)\//.test(url)) { | ||
| return "blogPost"; | ||
| } else if (/\.vice\.com\/?($|\w\w(\_\w\w)?\/?$)|\/(search\?q=)|topic\/|category\/|(latest|read)($|\?page=)/.test(url) && getSearchResults(doc, true) ) { |
This comment has been minimized.
This comment has been minimized.
adam3smith
Jul 26, 2018
Collaborator
I don't think you want that beginning \. before vice.com, do you? (doesn't match https://vice.com)
This comment has been minimized.
This comment has been minimized.
owcz
Jul 28, 2018
Author
Contributor
my understanding is that all vice.com addresses redirect to www.vice.com but I suppose the translator's target detection would have caught any bad addresses by this point
|
|
||
|
|
||
| function scrape(doc, url) { | ||
| var jsonURL = url+'?json=true'; |
This comment has been minimized.
This comment has been minimized.
adam3smith
Jul 26, 2018
Collaborator
You'll almost certainly want to clean the URL by doing url.replace(/#.+/, "") -- otherwise internal page navigation as well as social media origin info will get included in the jsonURL and will likely break it.
This comment has been minimized.
This comment has been minimized.
owcz
Jul 28, 2018
Author
Contributor
https://motherboard.vice.com/en_us/article/43pngb/how-to-make-your-own-medicine-four-thieves-vinegar-collective?utm_campaign=sharebutton appears to work fine and I haven't seen # parameters used, but will add anyway
 adam3smith
merged commit
adam3smith
merged commit 114abf4
into
zotero:master
Aug 4, 2018
1 check passed
This comment has been minimized.
This comment has been minimized.
|
Thanks! |
owcz commentedJul 10, 2017
•
edited
Handles every text-focused content site in the network. Some subsites (mainly i-D, Amuse i-D, and Vice News) vary significantly from the others, so some selectors were uglier than I'd prefer so as to accommodate. The rest more or less follow the same format. While i-D uses OpenGraph and might have benefited from using EM, the rest needed custom coding, so I thought it was best to build i-D support into a single Vice translator.
Need help with two issues:
Every snapshot I verified leads to a 404 page. Is there a workaround or should I just remove the snapshots altogether?
Some multis from the network sites that follow the same format have a weird issue:
https://broadly.vice.com/en_us
https://broadly.vice.com/en_us/topic/occult
https://waypoint.vice.com/en_us
https://waypoint.vice.com/en_us/latest
https://thump.vice.com/en_us/search?q=venetian
For instance, try any one of the above (all multis) and the saved articles will lack both author and tags, even though both do save properly if you run the scraper on the individual page (without the multi). There's something about the multi that leaves those two parameters out.
Scaffold is strange too. Add any one of those site's individual articles to the test, click "save", and it scrapes fine, as it normally does in the browser. But then "run" any one of those same individual articles and it'll ignore the site's authors and tags (same as above).
I tried to isolate the issue by removing everything that wasn't necessary for, say, broadly.vice.com's multi, but the scraper still returned null for each page's author/tags (even though the scraper returned the right results if run on the same pages individually). So not sure if it's an issue with the multi code or something with text()/attr() (#1277)