Join GitHub today
GitHub is home to over 36 million developers working together to host and review code, manage projects, and build software together.
Sign upPDF binary object extraction #302
Comments
 ruebot
added
enhancement
Scala
feature
DataFrames
labels
ruebot
added
enhancement
Scala
feature
DataFrames
labels
Jan 31, 2019
ruebot
added this to To do
in Binary object extraction
Jan 31, 2019
jrwiebe
added a commit
that referenced
this issue
Feb 1, 2019
 jrwiebe
moved this from To do
to In progress
in Binary object extraction
jrwiebe
moved this from To do
to In progress
in Binary object extraction
Feb 13, 2019
This comment has been minimized.
This comment has been minimized.
|
So, I think I have it working now building off of @jrwiebe's extract-pdf branch. I tested two scripts -- PDF binary extraction, and PDF details data frame -- on 878 GeoCities WARCs on tuna. PDF extractionScript import io.archivesunleashed._
import io.archivesunleashed.df._
val df = RecordLoader.loadArchives("/tuna1/scratch/nruest/geocites/warcs/9/*.gz", sc).extractPDFDetailsDF();
val res = df.select($"bytes").saveToDisk("bytes", "/tuna1/scratch/nruest/geocites/pdfs/9/aut-302-test", "pdf")
sys.exitJob $ time /home/ruestn/spark-2.4.3-bin-hadoop2.7/bin/spark-shell --master local[75] --driver-memory 300g --conf spark.network.timeout=10000000 --conf spark.executor.heartbeatInterval=600s --conf spark.driver.maxResultSize=4g --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.shuffle.compress=true --conf spark.rdd.compress=true --packages "io.archivesunleashed:aut:0.17.1-SNAPSHOT" -i /home/ruestn/aut-302-pdf-extraction/aut-302-pdf-extraction.scala 2>&1 | tee /home/ruestn/aut-302-pdf-extraction/logs/set-09.logResults Example output: https://www.dropbox.com/s/iwic5pwozikye5i/aut-302-test-925e8751447c08f2fbdf175e9560df7a.pdf Data frame to csvScript import io.archivesunleashed._
import io.archivesunleashed.df._
val df = RecordLoader.loadArchives("/tuna1/scratch/nruest/geocites/warcs/9/*gz", sc).extractPDFDetailsDF();
df.select($"url", $"mime_type", $"md5").orderBy(desc("md5")).write.csv("/home/ruestn/aut-302-pdf-extraction/df/9")
sys.exitJob $ time /home/ruestn/spark-2.4.3-bin-hadoop2.7/bin/spark-shell --master local[75] --driver-memory 300g --conf spark.network.timeout=10000000 --conf spark.executor.heartbeatInterval=600s --conf spark.driver.maxResultSize=4g --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.shuffle.compress=true --conf spark.rdd.compress=true --packages "io.archivesunleashed:aut:0.17.1-SNAPSHOT" -i /home/ruestn/aut-302-pdf-extraction/aut-302-pdf-df.scala 2>&1 | tee /home/ruestn/aut-302-pdf-extraction/logs/df-set-09.logResults $ wc -l set-09.csv
189036 set-09.csv
$ head set-09.csv
http://www.ciudadseva.com/obra/2008/03/00mar08/sombra.pdf,application/pdf,fffe565fe488aa57598820261d8907a3
http://www.geocities.com/nuclear_electrophysiology/BTOL_Bustamante.pdf,text/html,fffe1be9577b21a8e250408a9f75aebf
http://ca.geocities.com/stjohnnorway@rogers.com/childrens_choir.pdf,text/html,fffdd28bb19ccb5e910023b127333996
http://ca.geocities.com/kippeeb@rogers.com/Relationships/Tanner.pdf,text/html,fffdd28bb19ccb5e910023b127333996
http://www.scouts.ca/dnn/LinkClick.aspx?fileticket=dAE7a1%2bz2YU%3d&tabid=613,application/pdf,fffdb9e74a6d316ea9ce34be2315e646
http://www.geocities.com/numa84321/June2002.pdf,text/html,fffcad4273fec86948dc58fdc16b425b
http://geocities.com/plautus_satire/nasamirror/transcript_am_briefing_030207.pdf,text/html,fffcad4273fec86948dc58fdc16b425b
http://mx.geocities.com/toyotainnova/precios.pdf,application/octet-stream,fffc86181760be58c7581cd5b98dd507
http://geocities.com/mandyandvichy/New_Folder/money.PDF,text/html,fffc00bae548ee49a6a7d8bccbadb003
http://uk.geocities.com/gadevalleyharriers/Newsletters/_vti_cnf/Christmas07Brochure.pdf,text/html,fffbc9c1bcc2dcdd624bca5c8a9f1fc0Additional considerations
|
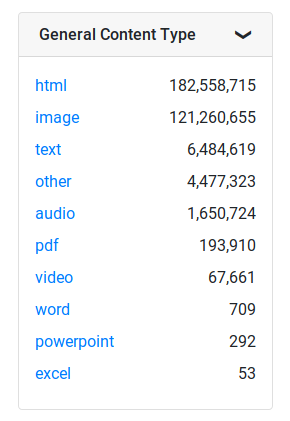
This comment has been minimized.
This comment has been minimized.
|
I'm not too concerned with credit for the commit, but I'm happy to make the PR. I would eventually like to put Tika MIME type detection back in, so we can find PDFs served without the correct type declaration. I'm running the same script on tuna with |
This comment has been minimized.
This comment has been minimized.
|
time... guess who didn't save it in the log file? I want to say it was around 8-10hrs for the PDF extraction, and around 12-14hrs for the csv. Oh, are you not getting the error with |
ruebot commentedJan 31, 2019
Using the image extraction process as a basis, our next set of binary object extractions will be documents. This issue is meant to focus specially on PDFs.
There may be a some tweaks to this depending on the outcome of #298.