Join GitHub today
GitHub is home to over 36 million developers working together to host and review code, manage projects, and build software together.
Sign upTrouble testing s3 connectivity #319
Comments
 ruebot
added
the
feature
label
ruebot
added
the
feature
label
Apr 30, 2019
This comment has been minimized.
This comment has been minimized.
|
Sorry for the delay on this. The problem is that our |
This comment has been minimized.
This comment has been minimized.
|
Great thanks Ian |
 jrwiebe
self-assigned this
jrwiebe
self-assigned this
May 30, 2019
jrwiebe
added a commit
that referenced
this issue
Jul 23, 2019
This comment has been minimized.
This comment has been minimized.
|
I just pushed a commit to branch @obrienben's above example works now.
A few notes:The version of
If you need to use Version 4, you'll have to add these lines to your code (change the
|
This comment has been minimized.
This comment has been minimized.
|
Updated above comment to reflect 5cab57b |
This comment has been minimized.
This comment has been minimized.
|
@obrienben can you pull down that branch, build it, and test it? |
This comment has been minimized.
This comment has been minimized.
|
Couldn't help myself and wanted to test. Worked flawlessly out of the box on
and then The right results! If this works on @obrienben's front let's move to a PR? |
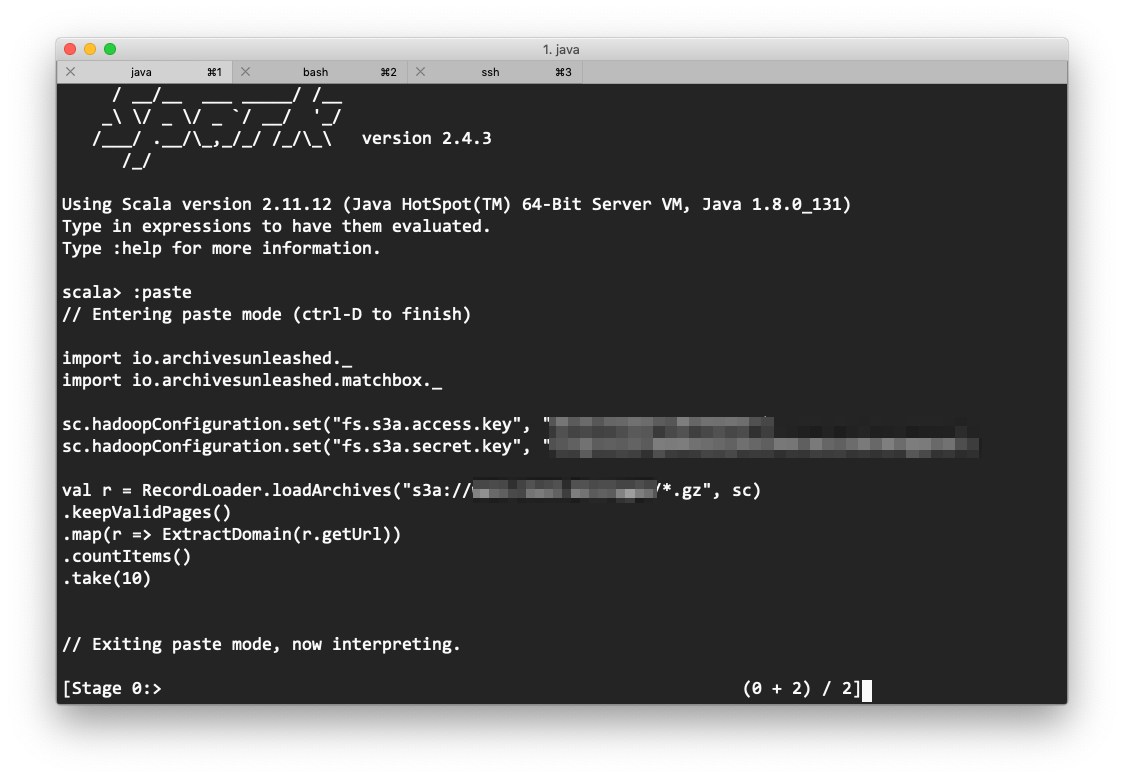
obrienben commentedApr 30, 2019
I'm just trying to test AUT connectivity to an s3 bucket (as per our conversation @ruebot ), and not having any luck. I thought I'd share what I've tried so far. Disclaimer - my spark and scala knowledge is limited.
I've setup an s3 bucket with some warcs in it, which i can access through plain python using boto3. So I know that my user and access credentials are working.
Based on the following Spark to s3 guide https://www.cloudera.com/documentation/enterprise/6/6.2/topics/spark_s3.html, this was my test AUT script:
Which gives me the following error:
Has anyone else had success supplying the toolkit with warcs from s3?