Join GitHub today
GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together.
Sign upAdd office document binary extraction. #346
Conversation
 ruebot
requested review from
ianmilligan1 and
jrwiebe
ruebot
requested review from
ianmilligan1 and
jrwiebe
Aug 15, 2019
This comment has been minimized.
This comment has been minimized.
codecov
bot
commented
Aug 15, 2019
•
Codecov Report
@@ Coverage Diff @@
## master #346 +/- ##
==========================================
- Coverage 75.2% 71.66% -3.54%
==========================================
Files 39 38 -1
Lines 1230 1426 +196
Branches 224 330 +106
==========================================
+ Hits 925 1022 +97
- Misses 214 245 +31
- Partials 91 159 +68 |
ruebot
added some commits
Aug 15, 2019
This comment has been minimized.
This comment has been minimized.
|
Will review in a few minutes! Re:
I think it'd probably make sense to include Or we could create a new one just for plain text files? |
This comment has been minimized.
This comment has been minimized.
|
I think it would make since to have a separate method for plain text files. I can add that here if there is consensus. |
This comment has been minimized.
This comment has been minimized.
|
I agree re. a separate method for plain text files. |
This comment has been minimized.
This comment has been minimized.
|
Separate method sounds good to me too. Thanks, @ruebot ! |
ianmilligan1
approved these changes
Aug 15, 2019
|
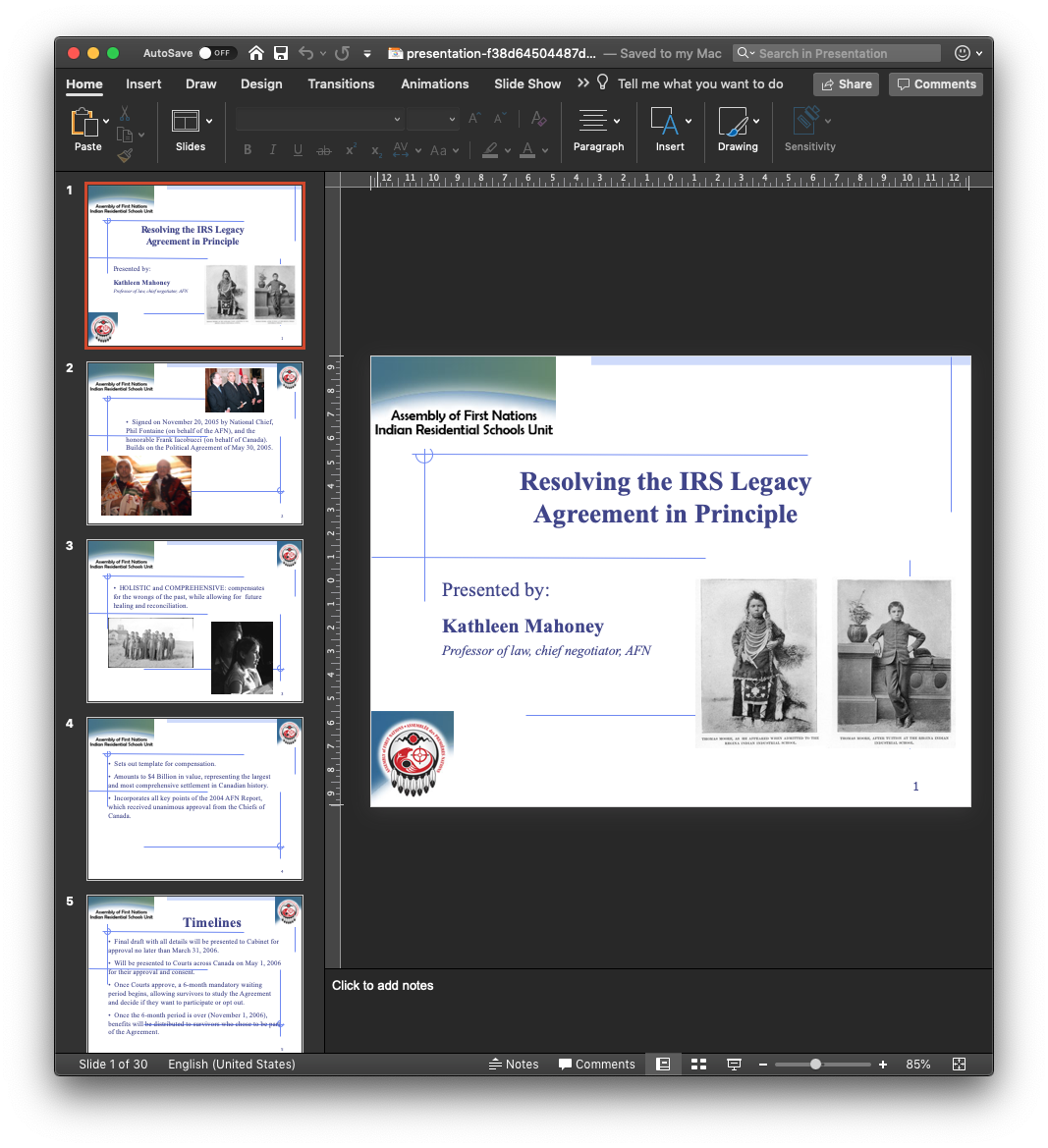
Tested on sample data and worked really well. Word documents and presentations worked perfectly (doc, rtf, and pps). Some interesting finds already.
We did get one false positive spreadsheet which was actually an HTML document: gist here if you're curious. |

This comment has been minimized.
This comment has been minimized.
|
@ianmilligan1 yeah, I got some |
This comment has been minimized.
This comment has been minimized.
|
This looks good. It looks pretty familiar, as I had a branch addressing #303 and/or #304, but I got stymied by the dependency issue and seem to have lost that work (I probably messed up some git stuff locally and re-cloned I removed the classifier from the pom and the build went fine. For the record, the reason it didn't work for @ruebot (he already knows this) is that the CDN used by JitPack to serve the jars cached an older version of the file we need, so his build was not getting the shaded artifact. |
This comment has been minimized.
This comment has been minimized.
|
The false positives come from filtering on file extension. I think we could remove most of those, except for "tsv" and "csv". |
This comment has been minimized.
This comment has been minimized.
|
@jrwiebe we actually need those. If I do have them, those tests will fail. Tika doesn't identify a bunch of those files in the test fixture. I originally had the method you suggested, and then when with the extension/url ends with. I'll create a enhancement ticket for breaking all those conditionals out after we get this merged. That's a good idea. |
This comment has been minimized.
This comment has been minimized.
|
@ruebot You don't have a log of the failed tests, do you? I'm interested to know which files Tika failed to identify correctly, and what it identified them as ( |
This comment has been minimized.
This comment has been minimized.
|
iirc |
This comment has been minimized.
This comment has been minimized.
|
Ok, give that a test again. I haven't tested it other than unit tests since I have to run now. I'll put it through it's paces again later this afternoon, and see if I can sort out the shading issue on my end again. |
jrwiebe
added some commits
Aug 15, 2019
This comment has been minimized.
This comment has been minimized.
|
@ruebot The unit tests failed when you weren't filtering on file extension because: I pushed a fix to (a), and removed the rest of the file extension filtering from the word processor document extractor. For (b), I left in the filtering on CSV and TSV extensions, but removed the other formats. Now the tests pass. BTW, should we add the dot before extensions when using |
This comment has been minimized.
This comment has been minimized.
|
@jrwiebe good call on the extensions. I was going to add |
This comment has been minimized.
This comment has been minimized.
|
@ruebot Go for it. I'm done with this for today. |
jrwiebe
approved these changes
Aug 15, 2019
ianmilligan1
requested changes
Aug 15, 2019
|
While this worked when I originally reviewed, it's now failing on the previous test script with: This is with for build and for shell. I can test again to see if this works on my machine once the classifier issues are sorted out? |
This comment has been minimized.
This comment has been minimized.
|
@ianmilligan1 yeah, I'm still getting the same thing |
This comment has been minimized.
This comment has been minimized.
|
@ianmilligan1 @ruebot Revert this change (i.e., put the classifier back in). You guys are getting the cached tika-parsers JAR (see my description of this problem). This might break use of |
This comment has been minimized.
This comment has been minimized.
|
@jrwiebe yeah, I've been fiddling with the JitPack interface in the morning/afternoon and keep on getting that cached JAR. We'll kick this can down the road, and hopefully resolve it before the release |
ruebot
referenced this pull request
Aug 16, 2019
Open
Add method for unknown extensions in binary extractions #343
ruebot
added some commits
Aug 16, 2019
This comment has been minimized.
This comment has been minimized.
|
I'm getting significantly less output after 8028aa3.
|
This comment has been minimized.
This comment has been minimized.
|
Try running tika-app detect on those same files. |
This comment has been minimized.
This comment has been minimized.
|
This comment has been minimized.
This comment has been minimized.
|
hrm, if I test with that tika-parsers commit you added, things blow up after a while, and I get this error: ...with a whole lot of apache-tika-adfasdfasdfasdfdasw.tmp files in my I also noticed that Spark behaved a little bit differently. I had stages with your commit, whereas with the original state of the pom in the PR, I don't have stages. It goes to straight tasks. I'll try and gist everything up here before I go to bed. |
This comment has been minimized.
This comment has been minimized.
|
Dealing with this Tika dependency thing over the last 6 months
|

This comment has been minimized.
This comment has been minimized.
Yup |
This comment has been minimized.
This comment has been minimized.
|
This comment has been minimized.
This comment has been minimized.
I probably should have been |
This comment has been minimized.
This comment has been minimized.
|
There shouldn't be any difference in behaviour between the two tika-parsers artifacts. The only difference besides where they are downloaded from is that one has a classifier as part of its versioning. |
ruebot commentedAug 15, 2019
•
edited
GitHub issue(s):
What does this Pull Request do?
to do this)
How should this be tested?
Additional Notes:
! r._1 == "text/html"or! r._1.startsWith("image/"). Or, is it worth leaving some of this noise in there?