Join GitHub today
GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together.
Sign upInvestigate what would be needed to include crawl-sites visualization #146
Comments
This comment has been minimized.
This comment has been minimized.
|
Here's an example of the output for other following along: http://lintool.github.io/warcbase/vis/crawl-sites/. I ran this on all the WALK collections, FWIW, and was able to do the full thing in a few minutes on a laptop if I remember correctly. Here's one of our 4-5TB ones: https://web-archive-group.github.io/WALK-CrawlVis/crawl-sites/ALBERTA_government_information_all_urls.html. |
This comment has been minimized.
This comment has been minimized.
|
FYI I dug back into our past workflow and am glad I did as it's a bit janky. Here's the latest workflow I was using to do this. https://github.com/web-archive-group/WALK-CrawlVis/blob/master/WORKFLOW.md Note that the major problem is the output from the domain count is different than what |
This comment has been minimized.
This comment has been minimized.
|
If we add an additional spark sub-job: We'll get output like this: Then we'll probably need to adapt After that, it'd just be following the path of the Sigmajs visualization for this implementation. |
This comment has been minimized.
This comment has been minimized.
|
This sounds promising! I'd defer to you on the implementation, but creating this file and then possibly adding it to the clean-up job is a good route forward? |
This comment has been minimized.
This comment has been minimized.
|
Easy part done. Now I have to port |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
To get something out of the door here, and make sure we can work with existing data, what if we took what powers the top 10 domains table, and make a column chart out of that? That should be pretty straightforward with Chartkick. |
This comment has been minimized.
This comment has been minimized.
|
Then close the door for now on the legacy bar chart since we'd have to create a new Spark job, and update the legacy d3.js work. If there's a lot of demand for this data from Spark in the future from users, we can add the data, and possibly integrate something like this in the user interface, or maybe the notebooks. |
This comment has been minimized.
This comment has been minimized.
|
That sounds like a great idea! And yeah, maybe make it a query point in the future to see if people would really like this. We could consider changing the domain script to generate not just absolute domain frequency but domain frequency by year (that would be straightforward), and then rig something up in the Jupyter notebook. |
This comment has been minimized.
This comment has been minimized.
|
This comment has been minimized.
This comment has been minimized.
|
Which yeah, as noted in your comment above, would be a simple tweak - just changing this line to (even simpler) Maybe that's worth doing anyways, which could give the domain notebook some heavier lifting to do – and in any case, make the domain derivative more useful? It'd get at the spirit of this issue, I think. |
This comment has been minimized.
This comment has been minimized.
|
Yeah, it'd definitely get to the issue, but my biggest worry with any changes to it is backwards compatibility on the 172T we've already analyzed. We'd probably just have to wrap things in a method that reads the first line of the derivative file to see if there is a date or not. If there is, continue with any we do with it. If not, break. If we're cool with that, I can update the Spark job in the work I'll do with Chartkick on this issue. |
This comment has been minimized.
This comment has been minimized.
|
Aye – that is persnickety, on both the AUK and Jupyter fronts (more the former than the latter, I think). Would Chartkick read the month/domain frequency data easily? Or would it work better with straightforward domain frequency count as is? I'm happy for you to make the final call if this is worth the effort or not, as you have a far better sense than I do. |
This comment has been minimized.
This comment has been minimized.
To explicitly mimic the d3 chart @lintool did, Not that I can see. Chartkick looks to be really great for charts with straightforward data (with my brief experience with it).
As is would be pretty easy, and give a much better look at the data than a table imo. Better? Not sure. It'd be a good question to pose to users sometime. |
This comment has been minimized.
This comment has been minimized.
|
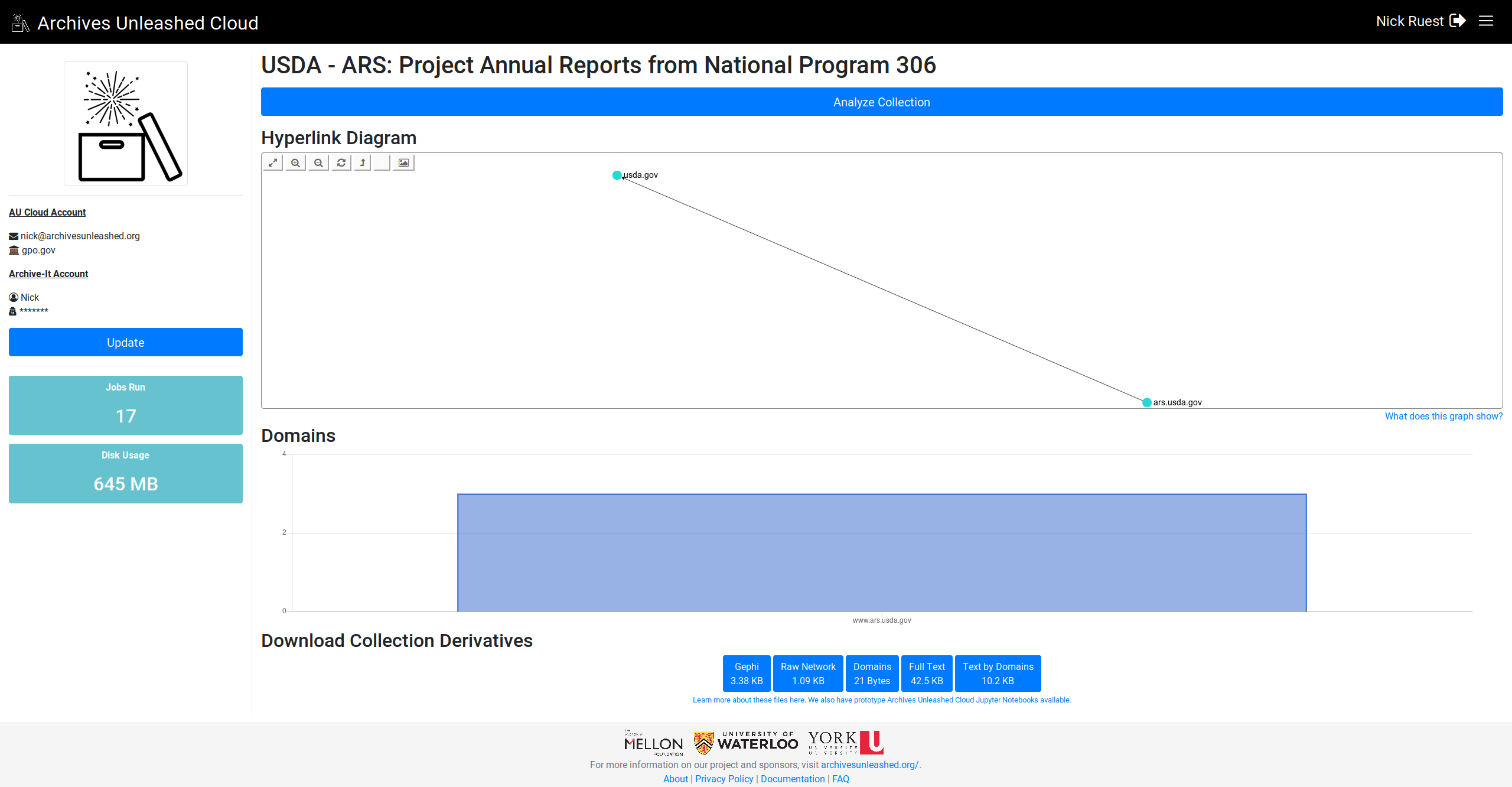
@ianmilligan1 @SamFritz @edsu (since this was related to the datathon feedback), let me know what you think (I'm pulling the top 25 domains if they're there):
|
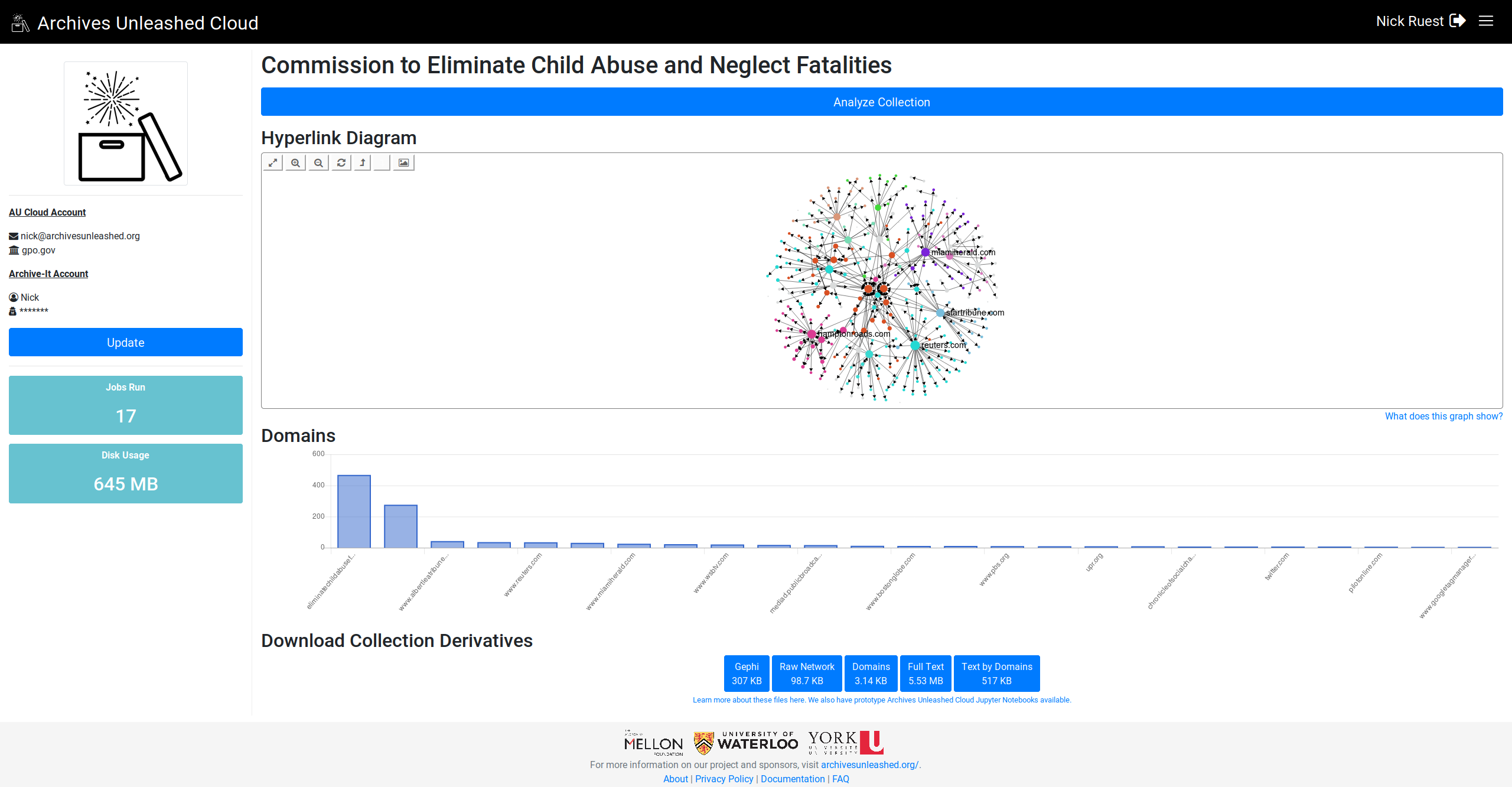
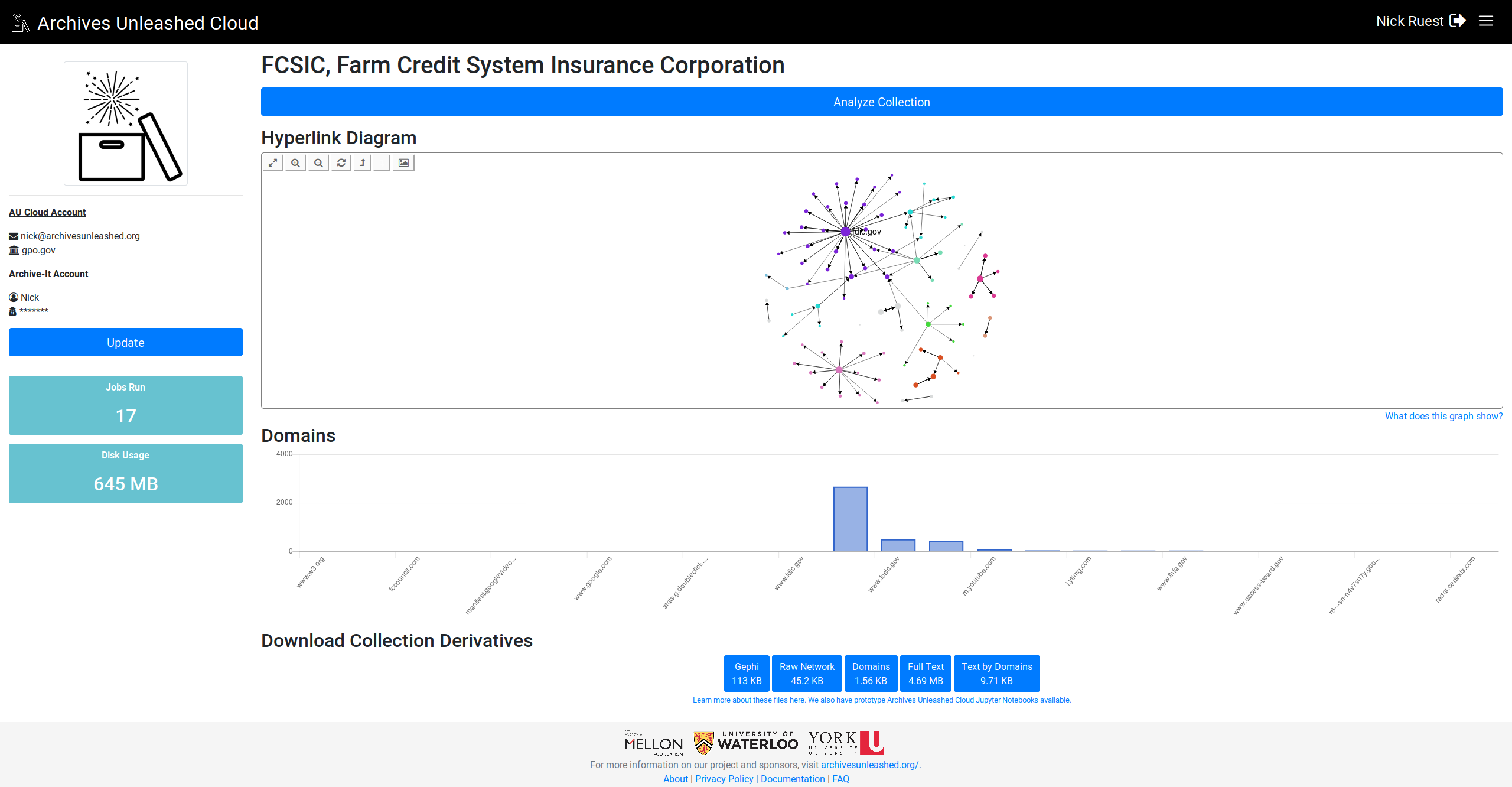
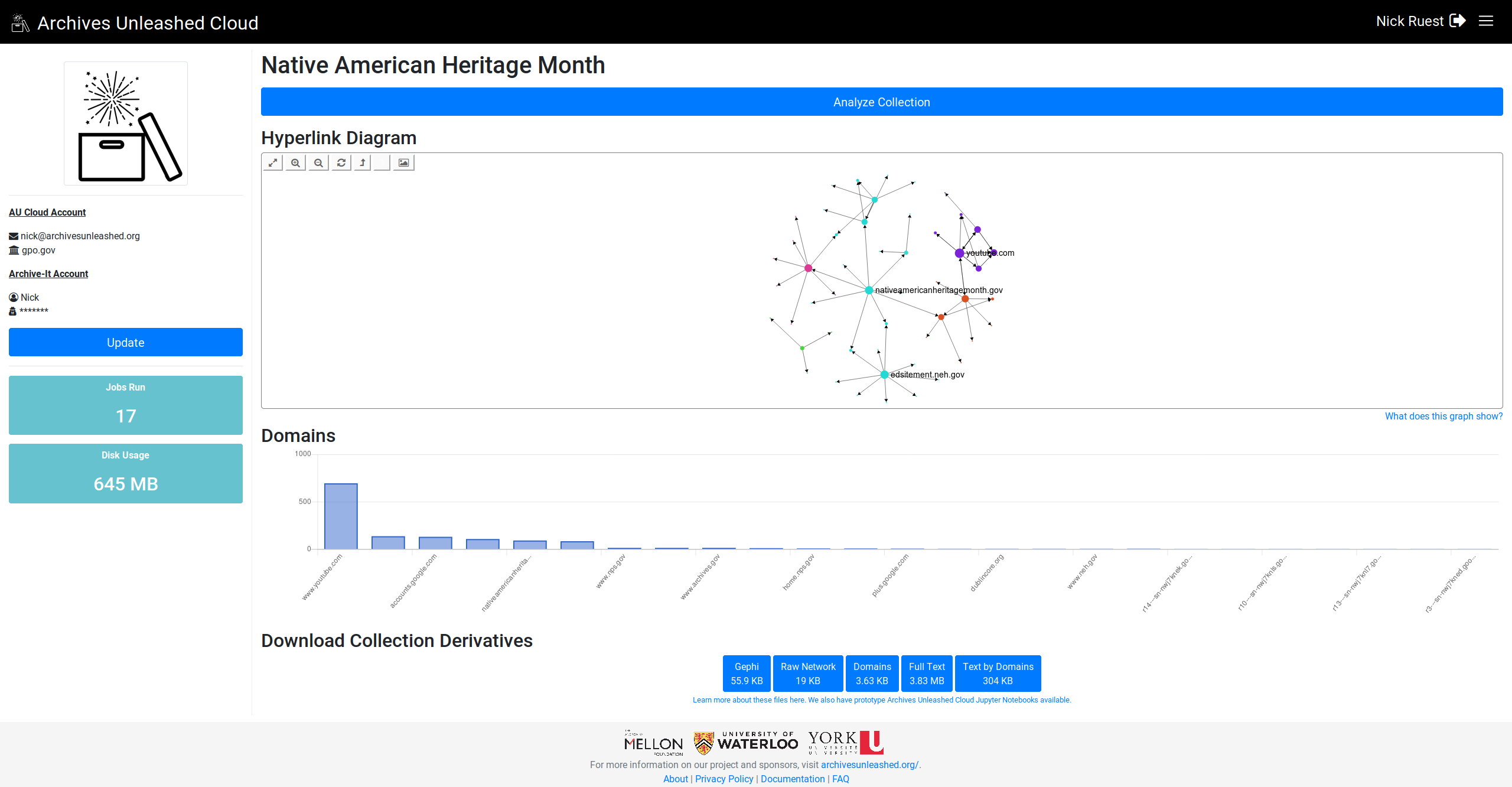
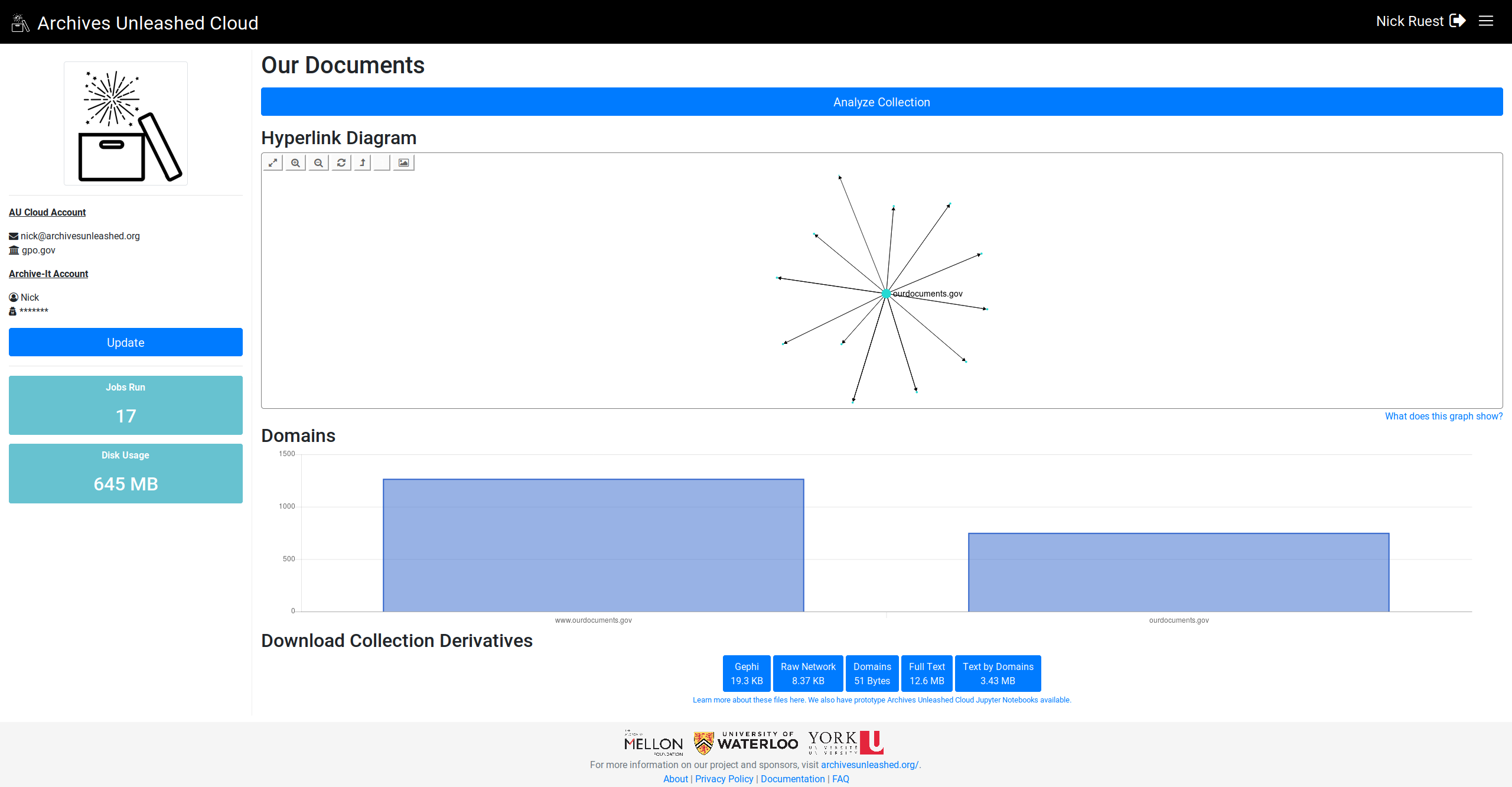
This comment has been minimized.
This comment has been minimized.
|
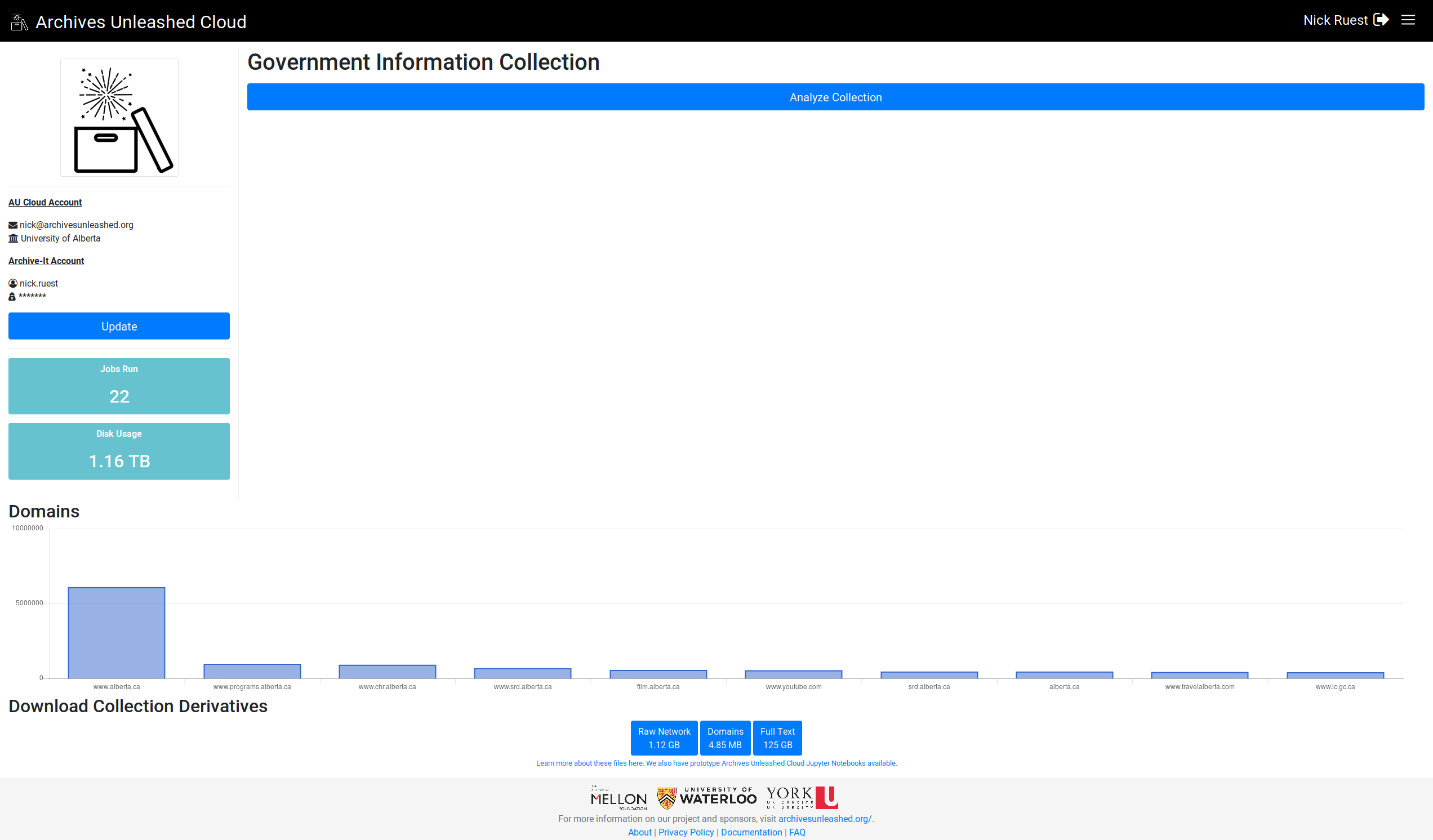
Looking great! Can't wait to see this rolled out! Is something funky happening with the labels – the columns don't always have labels, maybe when there are too many of them? And in the FCSIC screenshot above, the most frequent domains are in the middle of the graph as opposed to at the left. In general, they seem to be declining frequency left -> right? |
This comment has been minimized.
This comment has been minimized.
|
This looks great @ruebot! :) The only thing noticeable was described by @ianmilligan1 ^^ |
This comment has been minimized.
This comment has been minimized.
|
Cool. I'll work on sorting them, and see if I can get the label to display for all of them. |
This comment has been minimized.
This comment has been minimized.
|
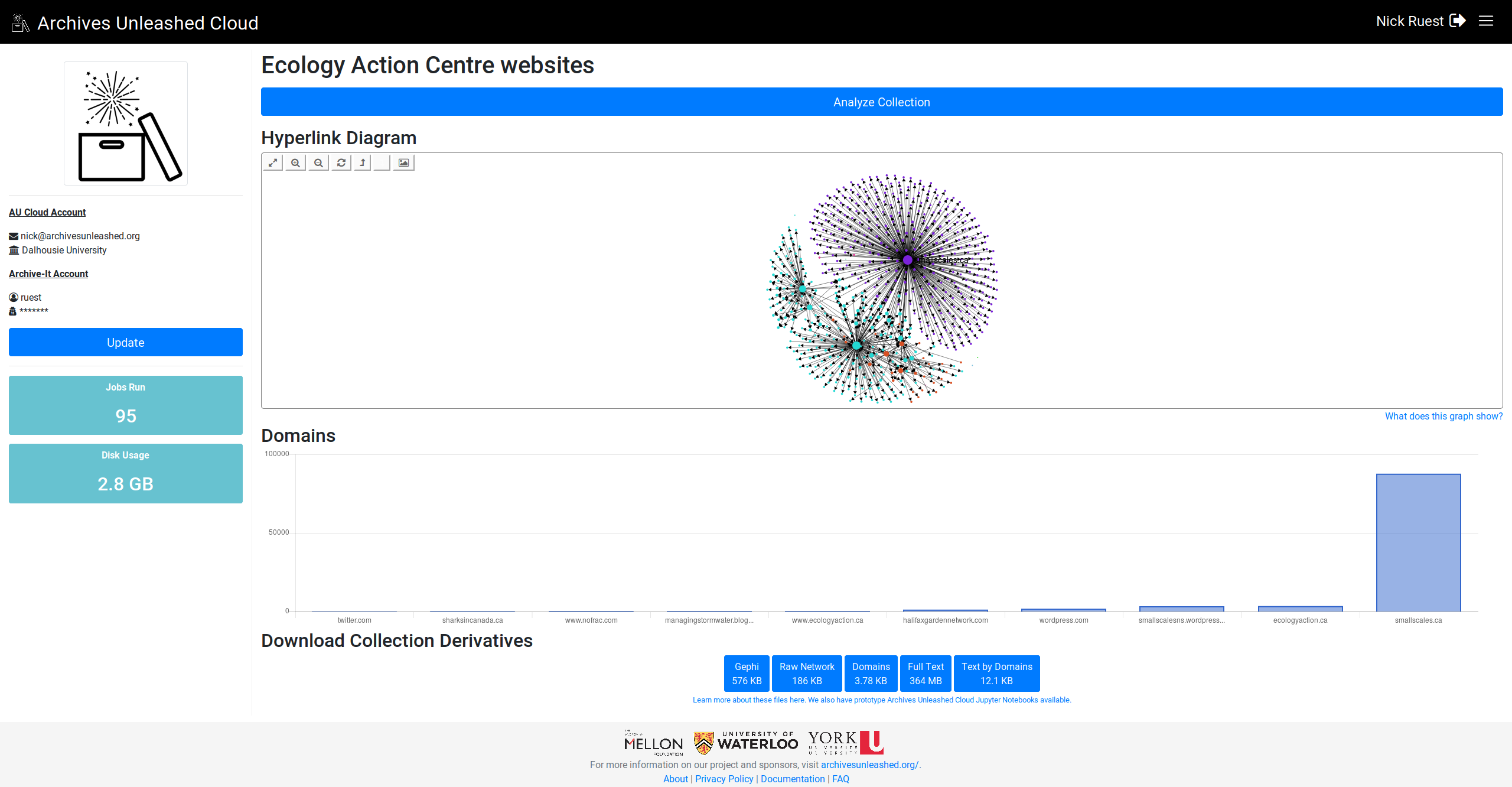
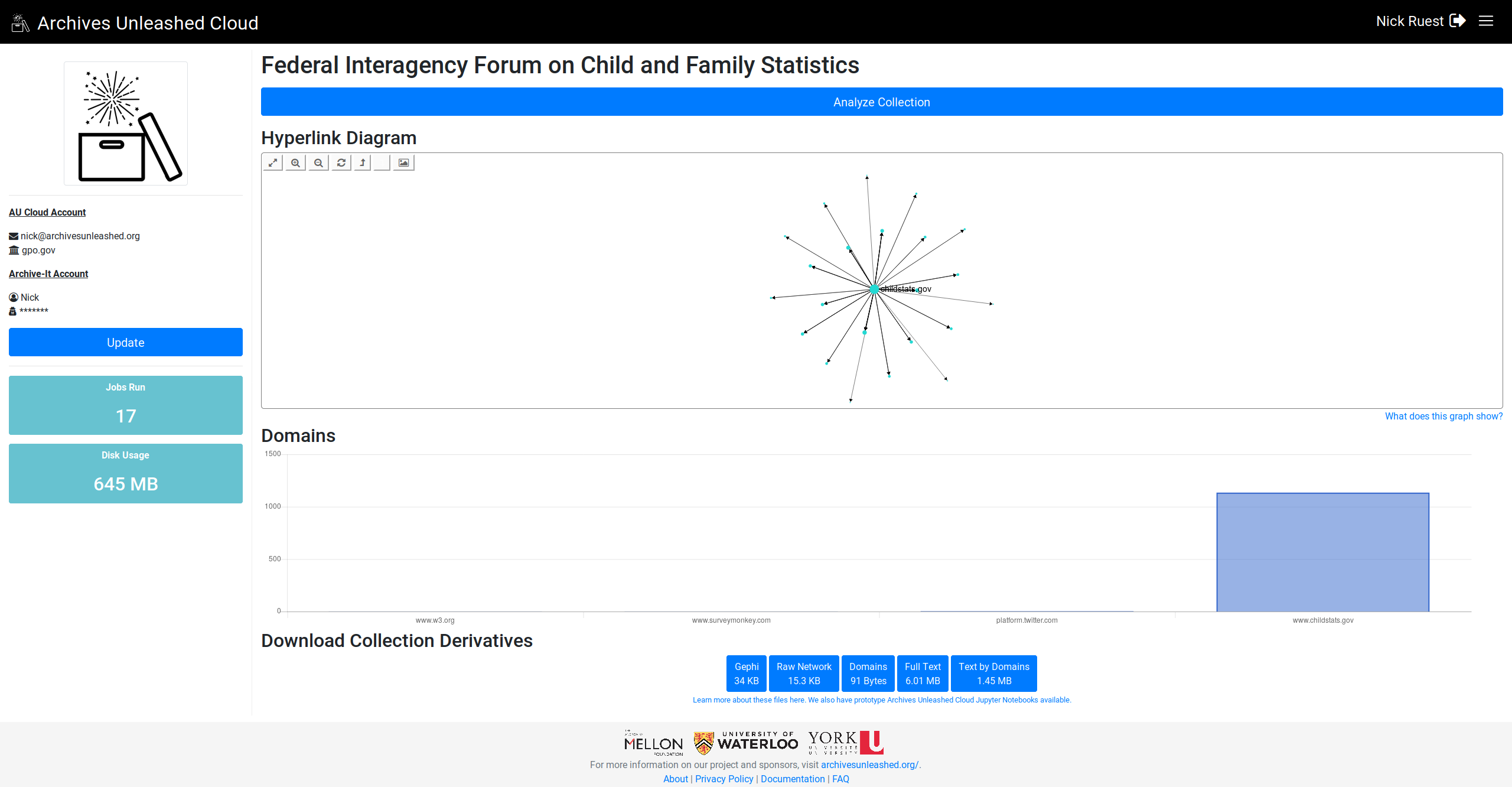
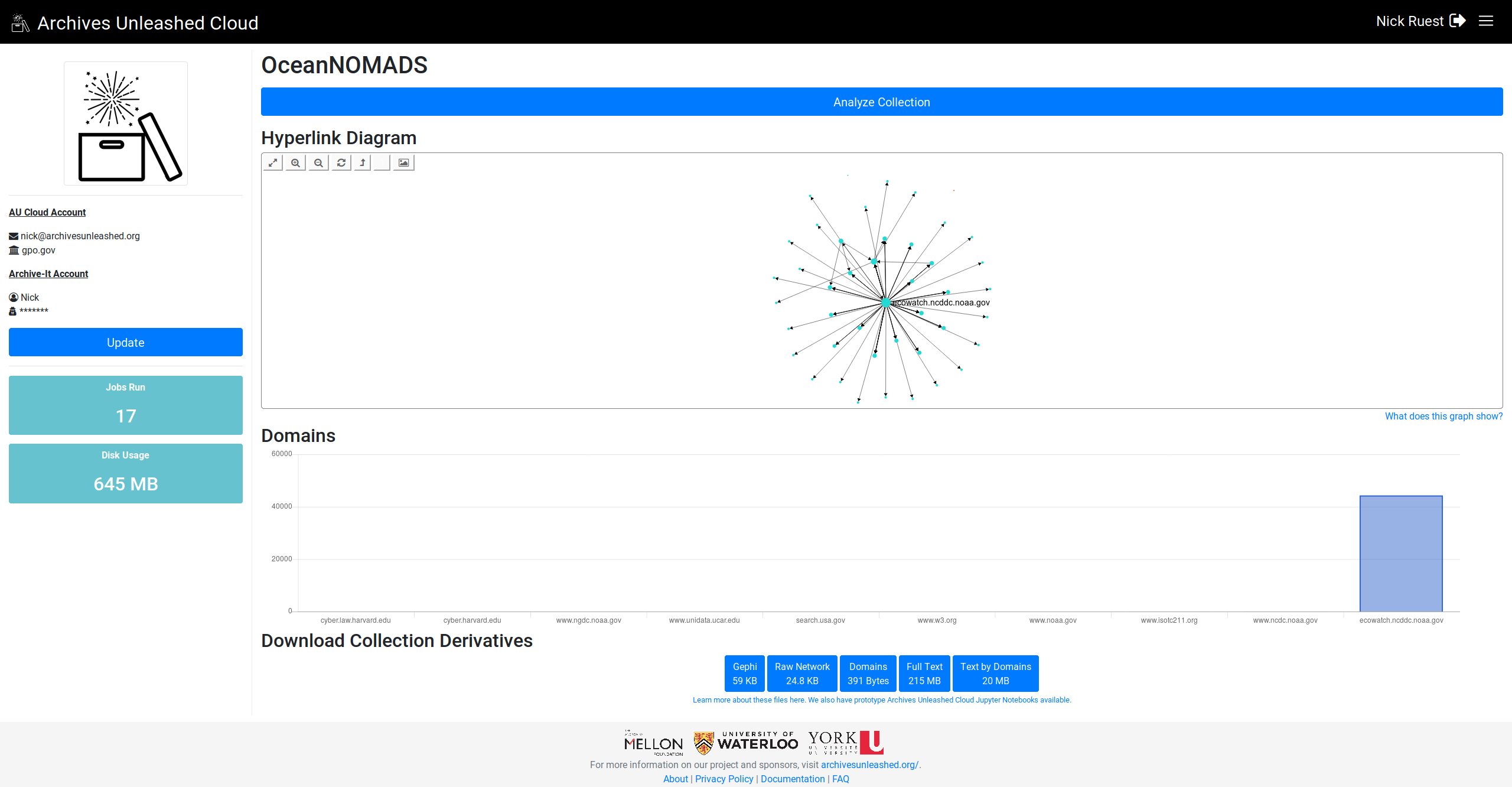
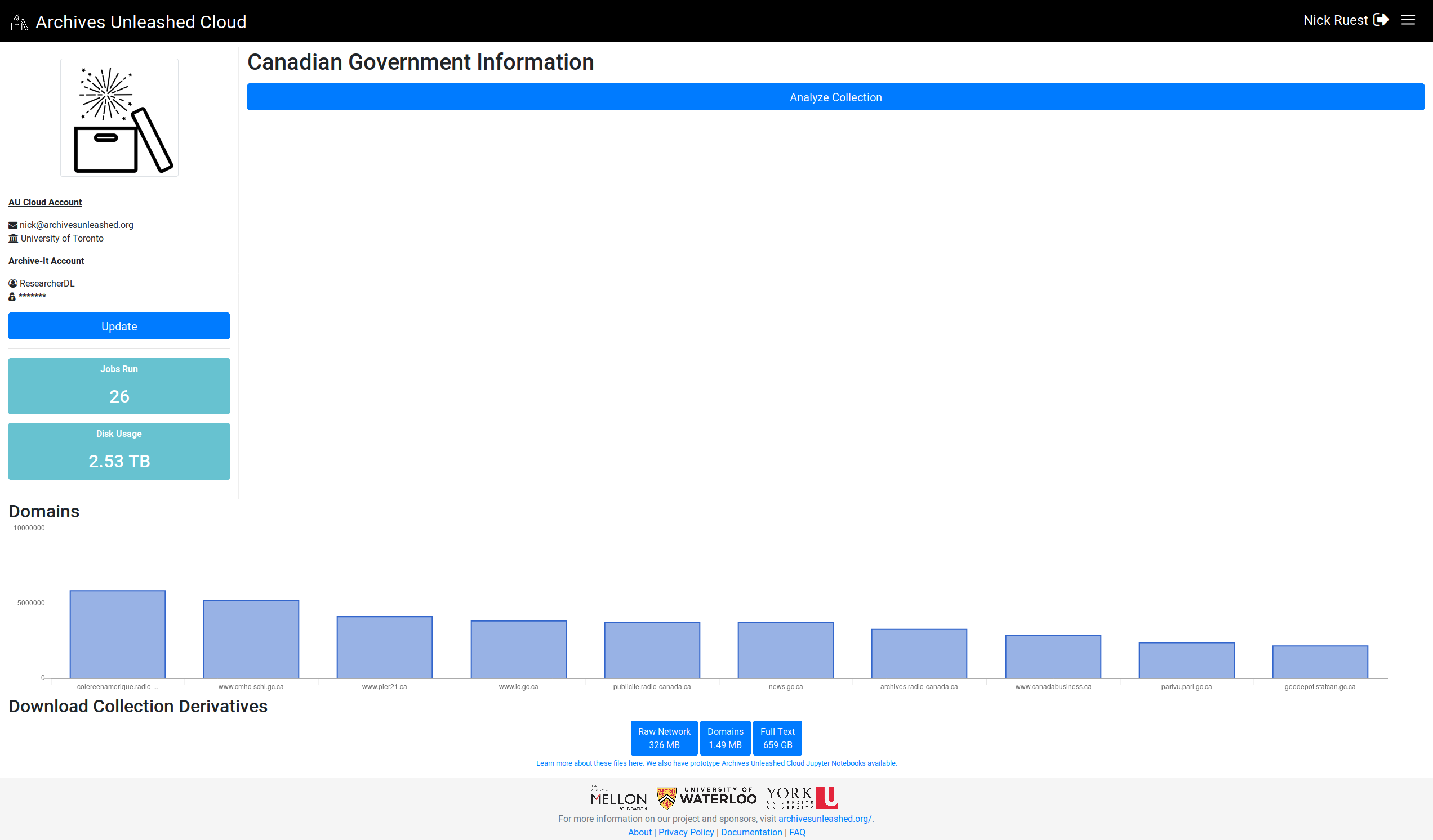
Here we go. Let me know what you think (especially, do you want largest on left or right?)
|
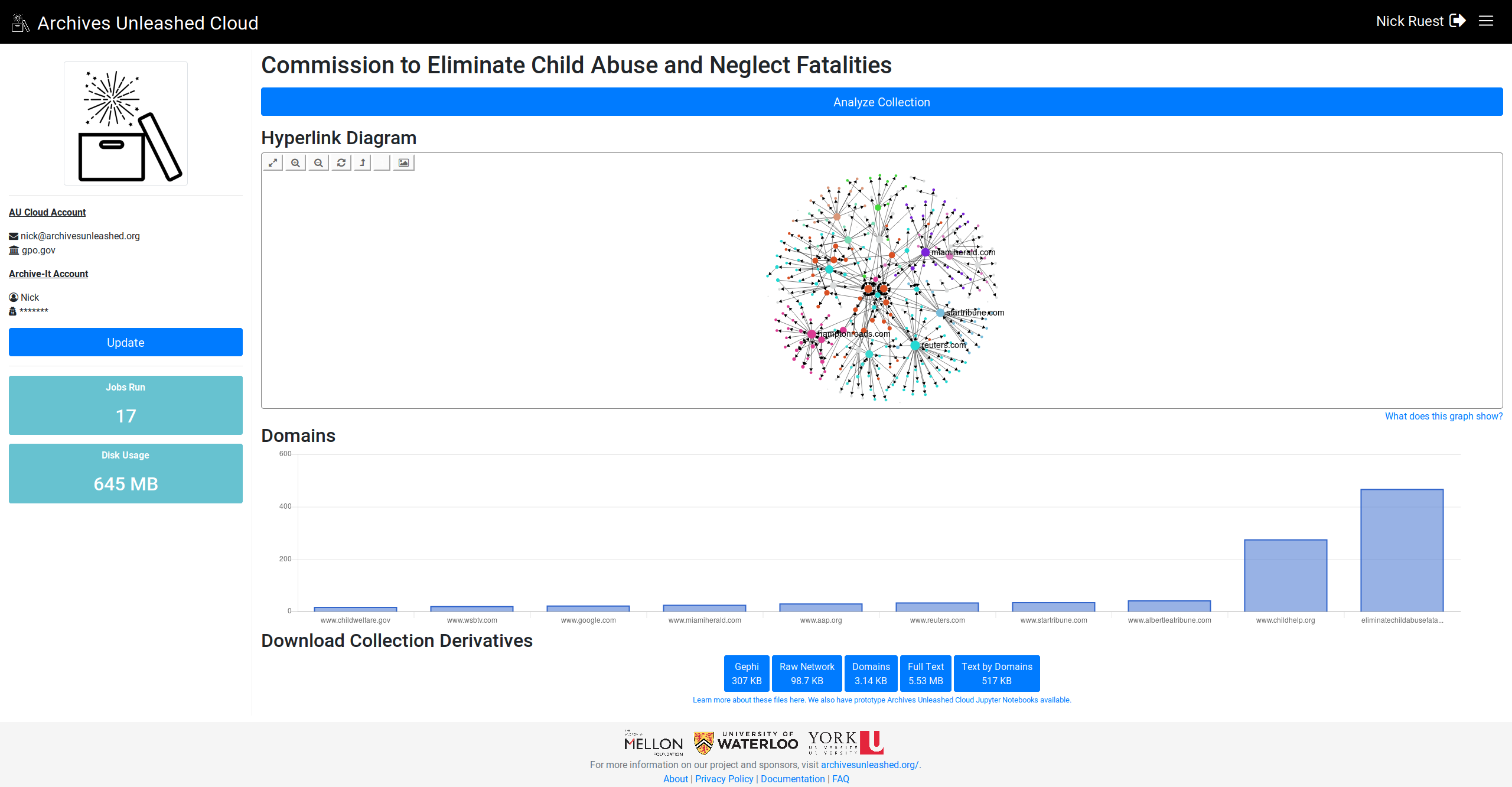
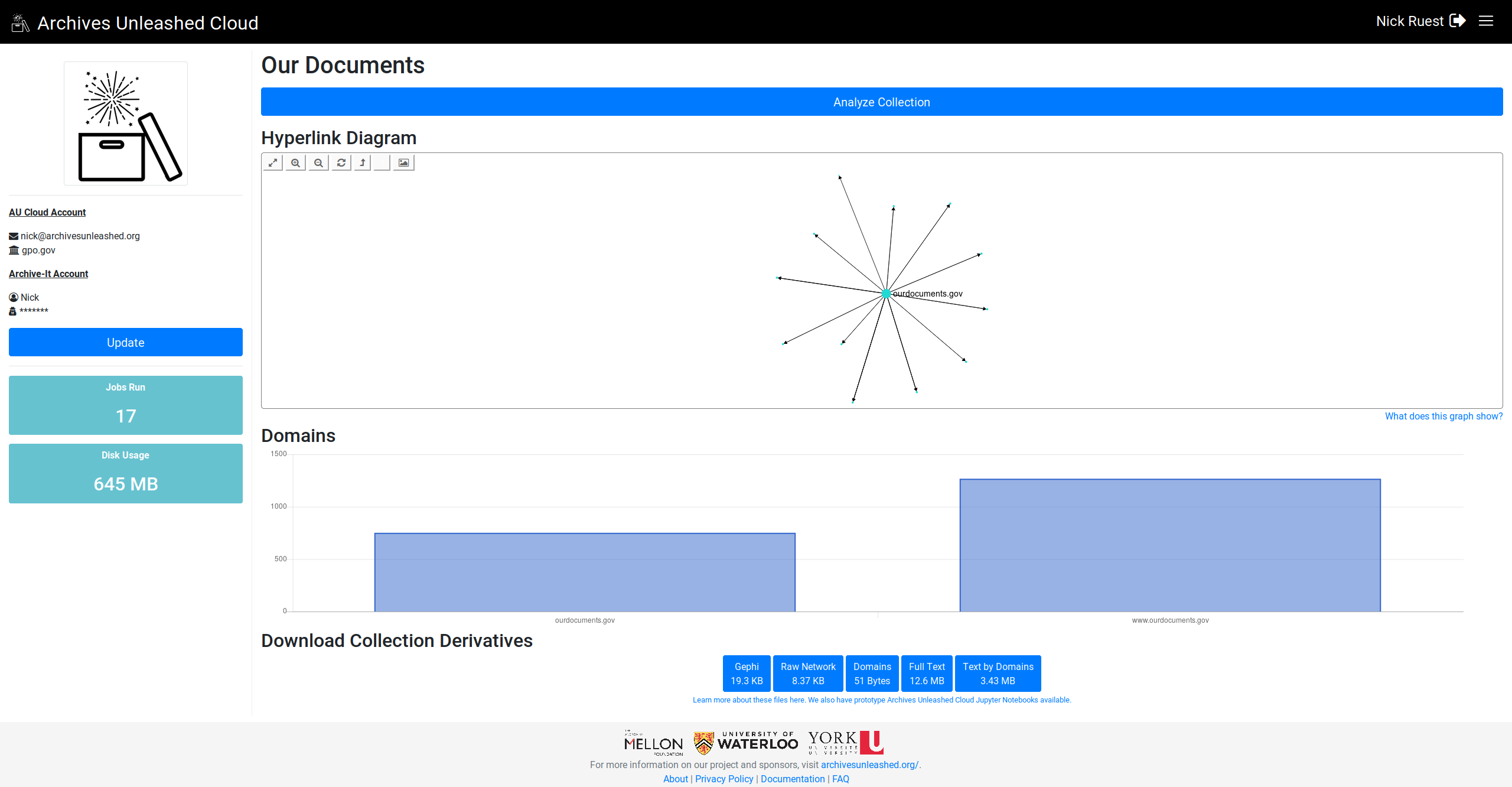
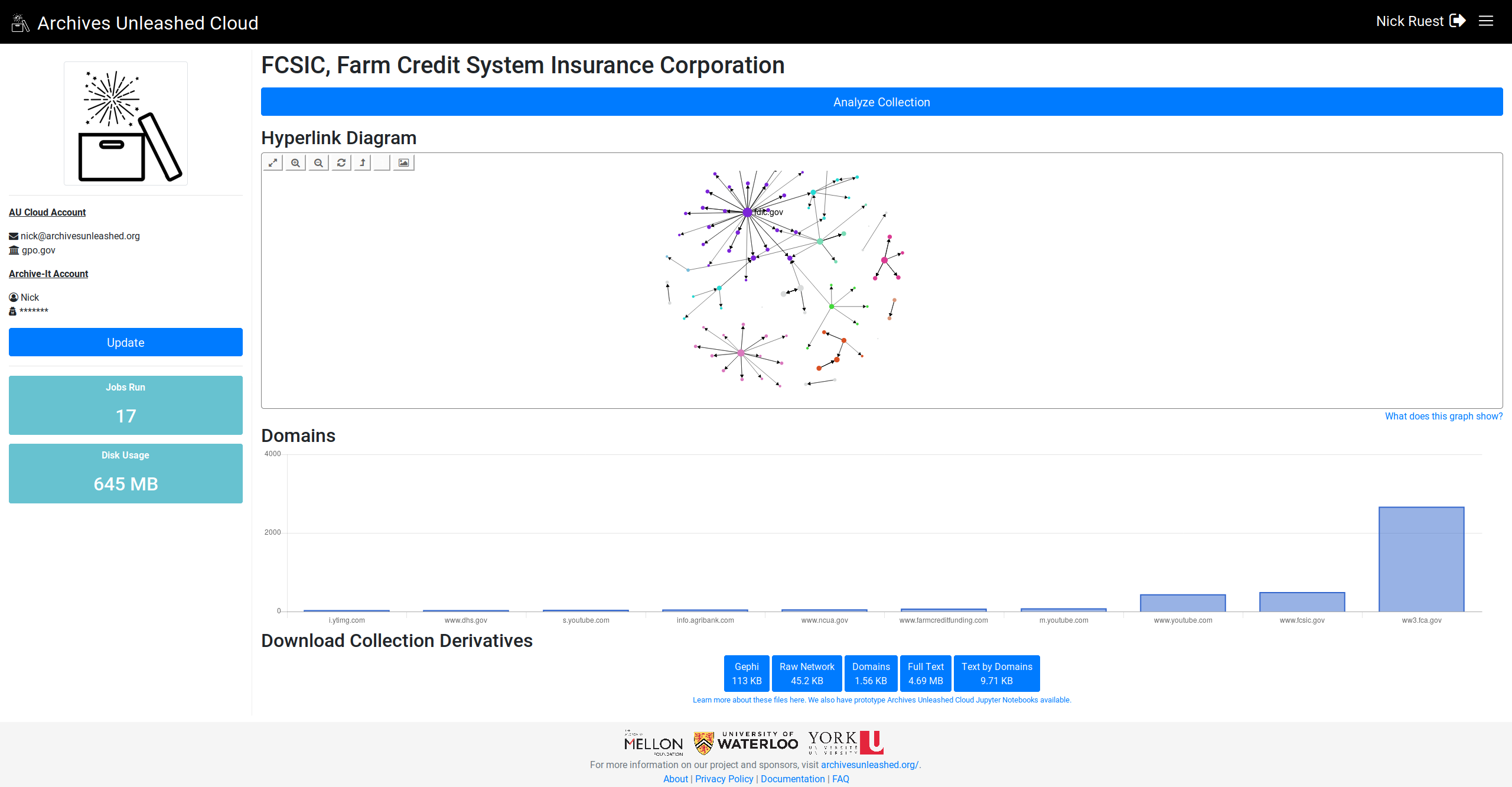
This comment has been minimized.
This comment has been minimized.
|
Looking great! I would probably prefer the larger on left if possible? |
This comment has been minimized.
This comment has been minimized.
|
Nice! Since we read left to right, I think it would make sense to read the chart big (left) to small (right) |
This comment has been minimized.
This comment has been minimized.
|
Updated production. Poke around and let me know what you think. |
This comment has been minimized.
This comment has been minimized.
|
Looks great to me!
Close issue for the time being or keep open? |
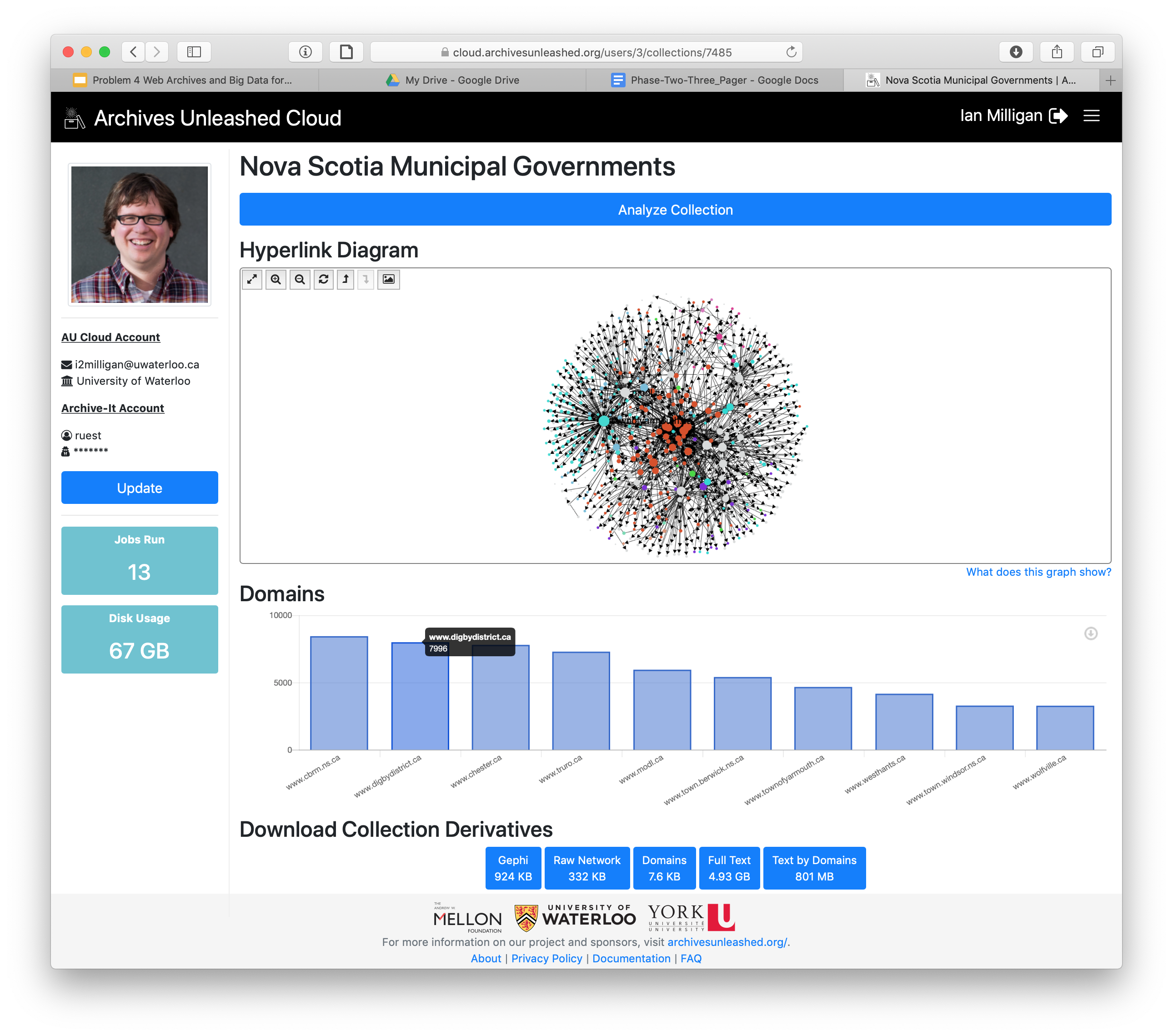
This comment has been minimized.
This comment has been minimized.
|
We gotta sort out the other bit with the additional Spark job, then we can close it. |
This comment has been minimized.
This comment has been minimized.
|
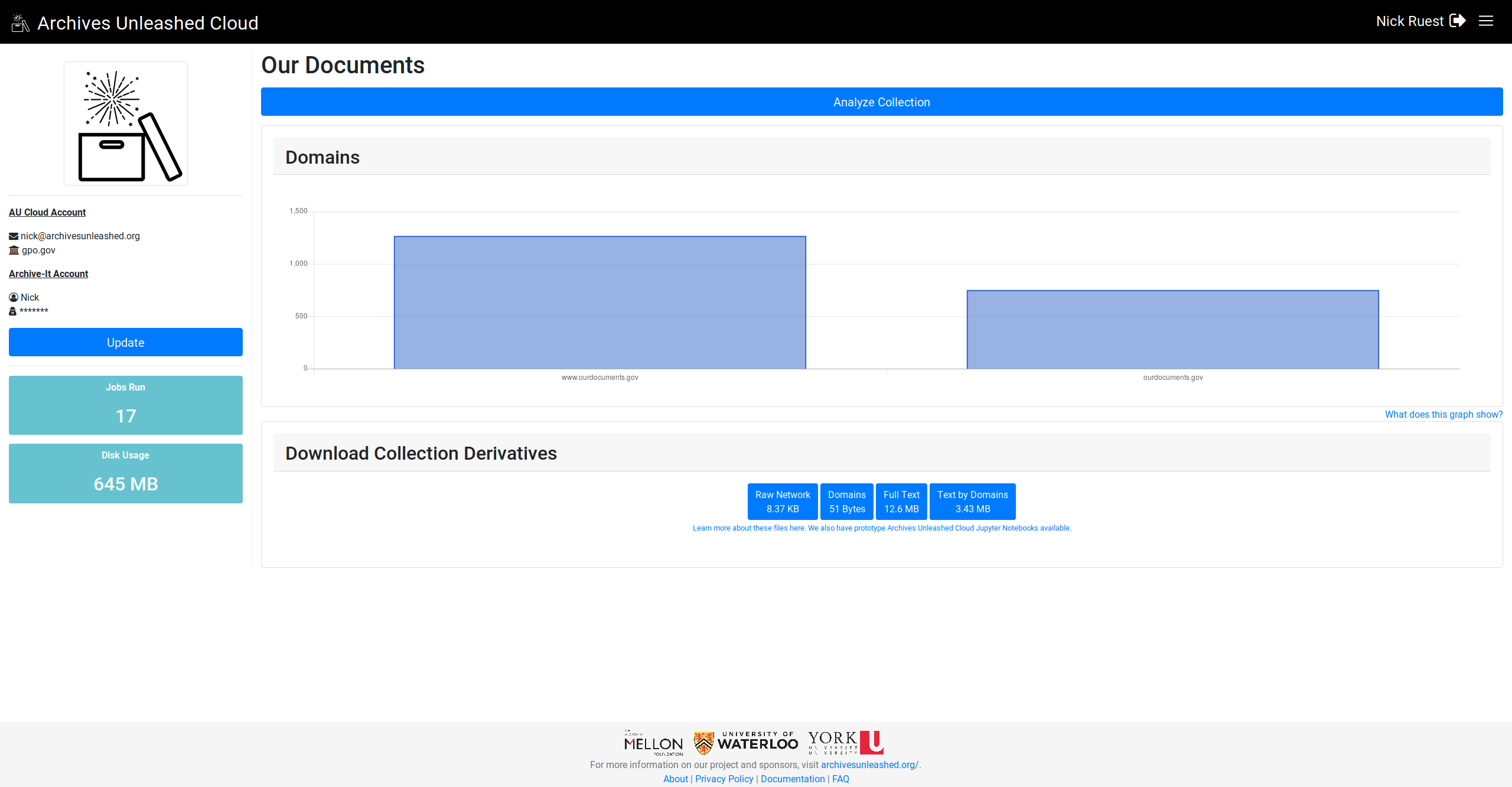
Gotta fix this formatting issue on the big collections where GraphPass won't run:
|
This comment has been minimized.
This comment has been minimized.
Sounds good - as discussed in Slack, I think, let’s chat about that on our next team call! And good catch on that formatting issue |
This comment has been minimized.
This comment has been minimized.
|
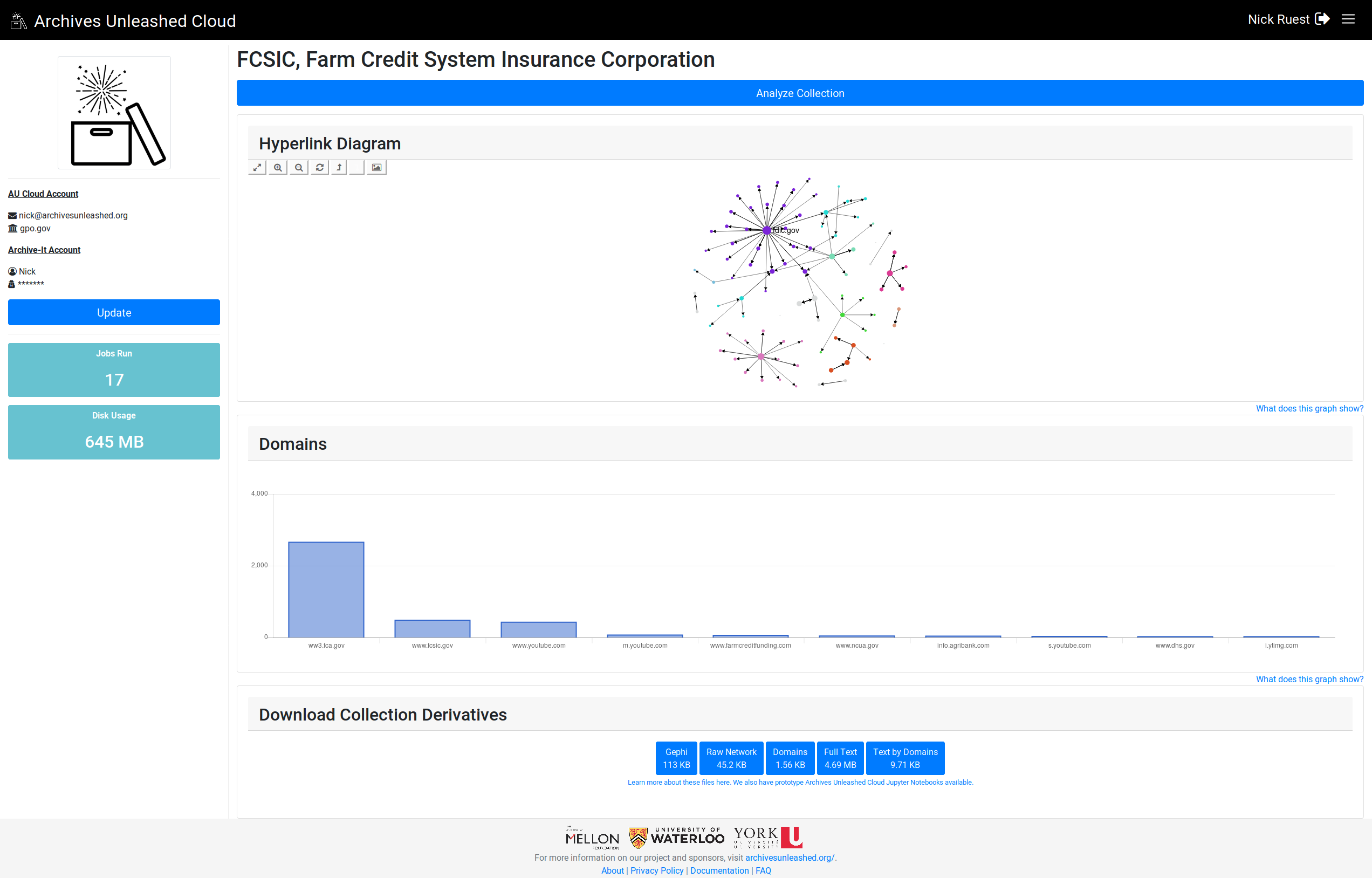
Fixed. Added a "What does this graph show?" under the bar chart. The tooltip reads: "This diagram Let me know if that text should change.
|
This comment has been minimized.
This comment has been minimized.
|
Good call on the "What does this graph show?" – text looks perfect to me, @ruebot ! |
ruebot commentedJul 3, 2018
See what is needed to add crawl-sites.
graph.js