Join GitHub today
GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together.
Sign upVideo binary object extraction #306
Comments
 ruebot
added
enhancement
Scala
feature
DataFrames
labels
ruebot
added
enhancement
Scala
feature
DataFrames
labels
Jan 31, 2019
ruebot
added this to To do
in Binary object extraction
Jan 31, 2019
ruebot
added a commit
that referenced
this issue
Jul 26, 2019
ruebot
moved this from To do
to In progress
in Binary object extraction
Aug 12, 2019
ruebot
self-assigned this
Aug 12, 2019
ruebot
added a commit
that referenced
this issue
Aug 12, 2019
ruebot
added a commit
that referenced
this issue
Aug 12, 2019
This comment has been minimized.
This comment has been minimized.
|
Ok, I have a basic framework setup in the branch. Pull down the branch, and do something along these lines (I had memory issues, so I did my whole Spark config thing): 306-pdf-audio-video-extract.scala import io.archivesunleashed._
import io.archivesunleashed.df._
val df_pdf = RecordLoader.loadArchives("/home/nruest/Projects/au/sample-data/geocites/1/*gz", sc).extractPDFDetailsDF();
val res_pdf = df_pdf.select($"bytes", $"extension").saveToDisk("bytes", "/home/nruest/Projects/au/sample-data/306-307-test/pdf", "extension")
val df_audio = RecordLoader.loadArchives("/home/nruest/Projects/au/sample-data/geocites/1/*gz", sc).extractAudioDetailsDF();
val res_audio = df_audio.select($"bytes", $"extension").saveToDisk("bytes", "/home/nruest/Projects/au/sample-data/306-307-test/audio", "extension")
val df_video = RecordLoader.loadArchives("/home/nruest/Projects/au/sample-data/geocites/1/*gz", sc).extractVideoDetailsDF();
val res_video = df_video.select($"bytes", $"extension").saveToDisk("bytes", "/home/nruest/Projects/au/sample-data/306-307-test/video", "extension")
sys.exitI have a whole lot of audio, pdf, and video files. Considerations
@jrwiebe @lintool @ianmilligan1 let me know what you think. |
This comment has been minimized.
This comment has been minimized.
|
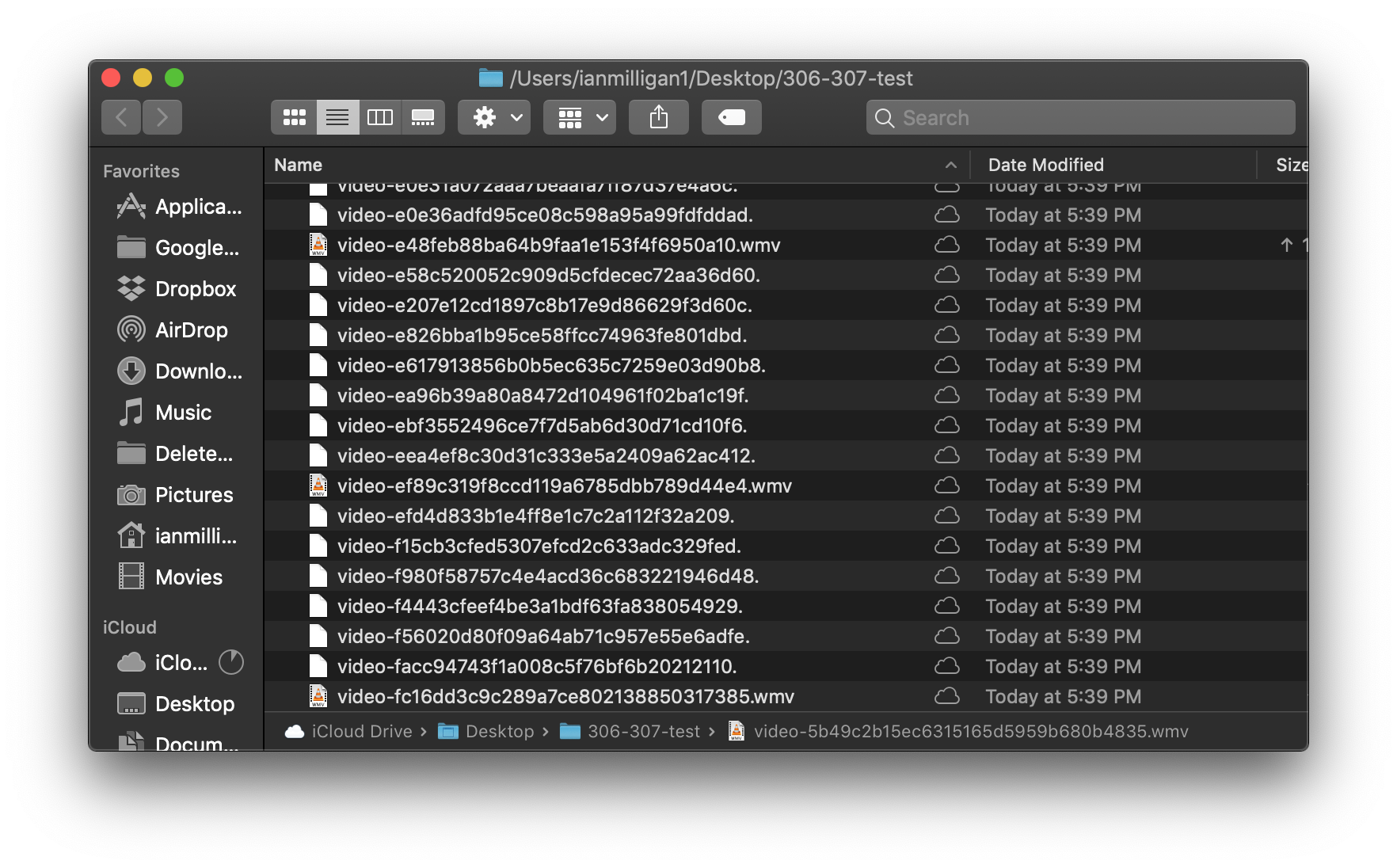
Woohoo, this is looking great. Congrats @ruebot! I've tested locally on our CPP Sample Data and all the extractors are working on the data. Some fun PDFs and lots of weird political talk radio and interview clips. FWIW, at least on this weird CPP collection subset from 2009, it's having trouble getting any extensions for video (it found a few wmv and the rest are all sans extension).
I don't know the best route on your questions #2 and #3 so will leave that to the more qualified @jrwiebe and @lintool. |
This comment has been minimized.
This comment has been minimized.
|
I'm not sure about this method of getting the extension. I think the reason @ianmilligan1 was getting so many videos without extension is that you're just getting the extension based on the URL. It's easy to think of examples of how audio or video files might be served without containing the file extension. I think a better way to get the extension is based on the MIME type. There isn't a 1:1 mapping between MIME and extension, so perhaps we combine this with URL analysis. I've created a branch that implements this method. I just finished running a test with it right now. It was working fine until the end, when it failed with (Aside: If you look at the branch's commit history you'll see I modified the POM. This is because the shading I did that somehow resolved #302 actually did not relocate (i.e., rename) |
ruebot commentedJan 31, 2019
Using the image extraction process as a basis, our next set of binary object extractions will be documents. This issue is meant to focus specially on video objects.
There may be a some tweaks to this depending on the outcome of #298.