Join GitHub today
GitHub is home to over 36 million developers working together to host and review code, manage projects, and build software together.
Sign upMIDAS Journal Translator #1030
Conversation
zuphilip
reviewed
Apr 10, 2016
| splitDownloadPath = downloadAllXPath.iterateNext().value.split('/'); | ||
| version=splitDownloadPath[splitDownloadPath.length-1] | ||
| newItem.extra="Revision: " + version | ||
| newItem.issue=splitDownloadPath[splitDownloadPath.length-2] |
This comment has been minimized.
This comment has been minimized.
zuphilip
reviewed
Apr 10, 2016
| //Zotero.debug("splitname"); | ||
| //Zotero.debug(splitname); | ||
| var z=1; | ||
| name=""; |
This comment has been minimized.
This comment has been minimized.
zuphilip
reviewed
Apr 10, 2016
| "translatorID": "86c35e86-3f97-4e80-9356-8209c97737c2", | ||
| "label": "MIDAS Journals", | ||
| "creator": "Rupert Brooks", | ||
| "target": "(insight-journal|midasjournal|vtkjournal).org/browse/publication", |
This comment has been minimized.
This comment has been minimized.
zuphilip
Apr 10, 2016
Collaborator
What is in front this? Normally we have something like ^https?://(www)?. Can we do this here also?
Moreover, escape the point in the regexp.
This comment has been minimized.
This comment has been minimized.
|
Can you give some specific examples for your translator? |
aurimasv
reviewed
Apr 10, 2016
| */ | ||
|
|
||
| function detectWeb(doc, url) { | ||
| if (url.match("browse/publication")) return "journalArticle"; |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
this is already guaranteed by the target regexp above. Since the only required field for translation is item.title, you probably want to check here that you can get the title.
aurimasv
reviewed
Apr 10, 2016
| var namespace = doc.documentElement.namespaceURI; | ||
| var nsResolver = namespace ? function(prefix) { | ||
| if (prefix == 'x') return namespace; else return null; | ||
| } : null; |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
Drop all of this and, below, use ZU.xpath(doc, "your xpath here") for an element array or ZU.xpathText(doc, "your xpath here") for the .textContent of the elements.
aurimasv
reviewed
Apr 10, 2016
| var submittedXPath = doc.evaluate('//*[@id="publication"]/div[@class="submittedby"]', doc, nsResolver, XPathResult.ANY_TYPE, null); | ||
| var abstractXPath = doc.evaluate('//*[@id="publication"]/div[@class="abstract"]', doc, nsResolver, XPathResult.ANY_TYPE, null); | ||
| var downloadAllXPath = doc.evaluate('//a[contains(text(),"Download All")]/@href', doc, nsResolver, XPathResult.ANY_TYPE, null); | ||
| var pdfXPath1 = doc.evaluate('//a[contains(text(),"Download Paper")]/@href', doc, nsResolver, XPathResult.ANY_TYPE, null); |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
Move all of these down to where they are actually assigned to the Zotero item.
aurimasv
reviewed
Apr 10, 2016
| //var pdfXPath2 = doc.evaluate('//a[contains(text(),".pdf")]/@href', doc, nsResolver, XPathResult.ANY_TYPE, null); | ||
|
|
||
|
|
||
| pdfhref=pdfXPath1.iterateNext(); |
This comment has been minimized.
This comment has been minimized.
aurimasv
reviewed
Apr 10, 2016
| pdflink=tmp[0]+'//' +tmp[2]+pdfhref.value; | ||
| //Zotero.debug(pdflink); | ||
| } | ||
| datematch=new RegExp("on\\w+([0-9]+)\\-([0-9]+)\\-([0-9]+)"); |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
Instead of new RegExp(...) use /.../ (and you don't need to declare them ahead of time. Use "foo".match(/o/) instead of regexp.exec("foo"))
aurimasv
reviewed
Apr 10, 2016
| //Zotero.debug(pdflink); | ||
| } | ||
| datematch=new RegExp("on\\w+([0-9]+)\\-([0-9]+)\\-([0-9]+)"); | ||
| datematch=new RegExp("on +([0-9]+)\\-([0-9]+)\\-([0-9]+)"); |
This comment has been minimized.
This comment has been minimized.
aurimasv
reviewed
Apr 10, 2016
| newItem.issue=splitDownloadPath[splitDownloadPath.length-2] | ||
|
|
||
| var a=0; | ||
| while (a<authors.length) { |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
This (and below) should be a for loop. for (var i=0; i<authors.length; i++) { ...
aurimasv
reviewed
Apr 10, 2016
| name=name+splitname[z]+" "; | ||
| z=z+1; | ||
| } | ||
| name=name+splitname[0]; |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
Please leave a comment in the code of what kind of string you are processing in this whole block. I can see that you're reshuffling something like Prastawa M. into M. Prastawa and then calling cleanAuthor to parse it. It would be much simpler and cleaner to
var m = "Prastawa M.".match(/(\S+)\s+(.+)/);
item.creators.push({
firstName: m[2],
lastName: m[1],
creatorType: 'author'
})`
This comment has been minimized.
This comment has been minimized.
str4w
Apr 10, 2018
Author
Contributor
would be even better to take prestructured data from the XML, see below comment
aurimasv
reviewed
Apr 10, 2016
| if(pdfhref) { | ||
| newItem.attachments.push({ | ||
| title: newItem.publicationTitle+" "+newItem.issue + " v" + version + " PDF", |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
Simply "Full Text PDF" is sufficient. The specifics are available in the metadata
aurimasv
reviewed
Apr 10, 2016
| title: newItem.publicationTitle+" "+newItem.issue + " v" + version +" Snapshot", | ||
| url: url, | ||
| mimeType:"text/html" | ||
| }); |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
There is generally no reason to attach a snapshot if we're attaching a full text pdf
This comment has been minimized.
This comment has been minimized.
str4w
Apr 10, 2018
Author
Contributor
I see your point, but most of the other translators I looked at (at least ArXiv, and ACM) do this. It seems to be the standard practice.
aurimasv
reviewed
Apr 10, 2016
| } | ||
|
|
||
| function doWeb(doc, url) { | ||
| if(detectWeb(doc,url)=="journalArticle") { |
This comment has been minimized.
This comment has been minimized.
aurimasv
reviewed
Apr 10, 2016
| if(detectWeb(doc,url)=="journalArticle") { | ||
| var articles = new Array(); | ||
| articles = [url]; | ||
| Zotero.Utilities.processDocuments(articles, scrape, function(){Zotero.done();}); |
This comment has been minimized.
This comment has been minimized.
aurimasv
Apr 10, 2016
Contributor
I'm not sure what you're trying to do here. The page is already loaded. Why re-load it?
aurimasv
reviewed
Apr 10, 2016
| var articles = new Array(); | ||
| articles = [url]; | ||
| Zotero.Utilities.processDocuments(articles, scrape, function(){Zotero.done();}); | ||
| Zotero.wait(); |
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
As @zuphilip says, please provide some examples and, preferably, add test pages using Scaffold. |
 zuphilip
added
the
New Translator
label
zuphilip
added
the
New Translator
label
Nov 12, 2017
zuphilip
added
the
waiting
label
Jan 1, 2018
This comment has been minimized.
This comment has been minimized.
|
@str4w What is the status here? |
This comment has been minimized.
This comment has been minimized.
|
Oops. Honestly, I assessed the number of comments at the time as "Too large to complete this week", and then I totally forgot about it after that. It is back on my radar, I will try to look at it in the near future. |
This comment has been minimized.
This comment has been minimized.
|
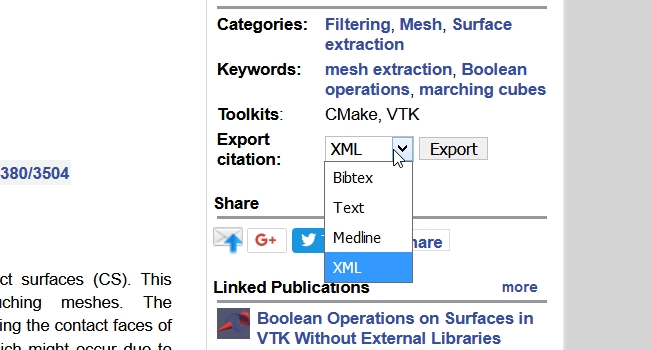
Okay, thank you for the response. Can you start with the test cases? I see that there is now also several export options, which we could also use instead of scraping from the website:
We could use for example the structured data in the XML for the authors (full first names, split into first and last names, several authors are split). What do you think? |
This comment has been minimized.
This comment has been minimized.
|
looking at this quickly, wouldn't it make sense to just import BibTeX or Medline (for which we already have import translators) and then add journal title and ISSN quickly based on the URL? |
This comment has been minimized.
This comment has been minimized.
|
BibTeX does not look that good, e.g. for http://www.vtkjournal.org/browse/publication/880 we have Medline format could work also as there are also the full first names there, but publication title seems missing and maybe more. That is the reason I asked for examples... |
This comment has been minimized.
This comment has been minimized.
|
right, publication titles seem to be missing everywhere -- that's why I thought we'd add them based on URL. |
This comment has been minimized.
This comment has been minimized.
|
Sorry this dragged so long. This should be improved from the last iteration. Questions - Looking at some of the other examples, sometimes they use More importantly, this would be cleaner and the data would be more complete if it could pull the exported XML (sadly, as the previous comments point out, that data is incomplete and we can't just use that for everything). To get that XML, need to make an HTTP post and parse the output - how does one do that - can the Zotero.doGet method do it? |
zuphilip
removed
the
waiting
label
Apr 15, 2018
zuphilip
added some commits
Apr 15, 2018
This comment has been minimized.
This comment has been minimized.
|
@str4w I worked directly on top of your work here and created a PR into your fork: str4w#1 . If you merge this PR then it will be automatically update here. There are some special functions which you can use in coding Zotero translators and they either start with We need a post call here and therfore I used |
This comment has been minimized.
This comment has been minimized.
|
Thanks for the explanations and improvements. I merged with my fork so it appears here. |
This comment has been minimized.
This comment has been minimized.
|
Okay, great. Let me know whether there is anything left from your point of view. |
This comment has been minimized.
This comment has been minimized.
|
I'm running a few tests to be sure. A couple things - I see that you have added multiples. However, I tried this link I tried this link http://www.insight-journal.org/browse/publication/921 and the doWeb returns the tags below. I don't understand the + and -. Is it normal? I am not actually using the autogenerated tags in Zotero, so this doesn't trouble me directly, just wondering. |
This comment has been minimized.
This comment has been minimized.
|
Okay, I added another path for this multiple with some filtering on the expected urls. Moroever, some clean-ups. Please merge again: str4w#2 Yes, what you see with the tags is normal. The differences which are indicated with the -/+ are just the ordering, which is performed alphabetically for the test cases. |
str4w
added some commits
Apr 16, 2018
This comment has been minimized.
This comment has been minimized.
|
I checked a bunch of articles, ran the tests, looks good. I added the ISSN tag, since it is available in many cases, why not have it? Are you sure you want the article number to go into the pages field? If that is consistent with what other translators do then it would make sense, it just doesn't fit the literal definition of that field as I understand it. Assuming the ISSN tag is ok with you and the page field for the article number was intentional, looks good to me, go for it. |
This comment has been minimized.
This comment has been minimized.
@adam3smith Do I remember correctly? Can you confirm (or correct) that saving an article id is best done in the (I will merge it as soon as we clarified this.) |
This comment has been minimized.
This comment has been minimized.
Yes, that's right |
zuphilip
merged commit d8bfa59
into
zotero:master
Apr 16, 2018
1 check passed
This comment has been minimized.
This comment has been minimized.
|
Merged! |
str4w commentedMar 23, 2016
This is a translator for the journals hosted by Kitware - Insight Journal, VTK Journal, etc.