Join GitHub today
GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together.
Sign up.webpages() additional tokenized columns? #402
Comments
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
|
Might be worth giving Spark NLP a more exhaustive look again. |
This comment has been minimized.
This comment has been minimized.
|
We should probably add a language column, and we can do that pretty easily with |
This comment has been minimized.
This comment has been minimized.
|
I don't think we should include tokenizations as an additional column. My general thinking is to be as conservative as possible - unless there are scholarly clamoring for a pre-generated field, don't include it. Otherwise, the derivatives will just become larger and larger and more unwieldy over time. |
This comment has been minimized.
This comment has been minimized.
|
Another reason against - there is no such thing as a "canonical" tokenization. Every tokenizer behaves differently... so unless a scholar happens to want exactly your tokenization, it's not going to be useful... |
This comment has been minimized.
This comment has been minimized.
|
To reduce time required for tokenization, if the scholar can setup a distributed environment, we can add a guide for text analysis in pyspark. Instead of simple python where we are converting to pandas dataframe, we can use pyspark dataframe and perform analytics on it using mllib. |
This comment has been minimized.
This comment has been minimized.
|
For basic NLP, spaCy https://spacy.io/ has become the go-to toolkit... try it from the Python end? |
This comment has been minimized.
This comment has been minimized.
|
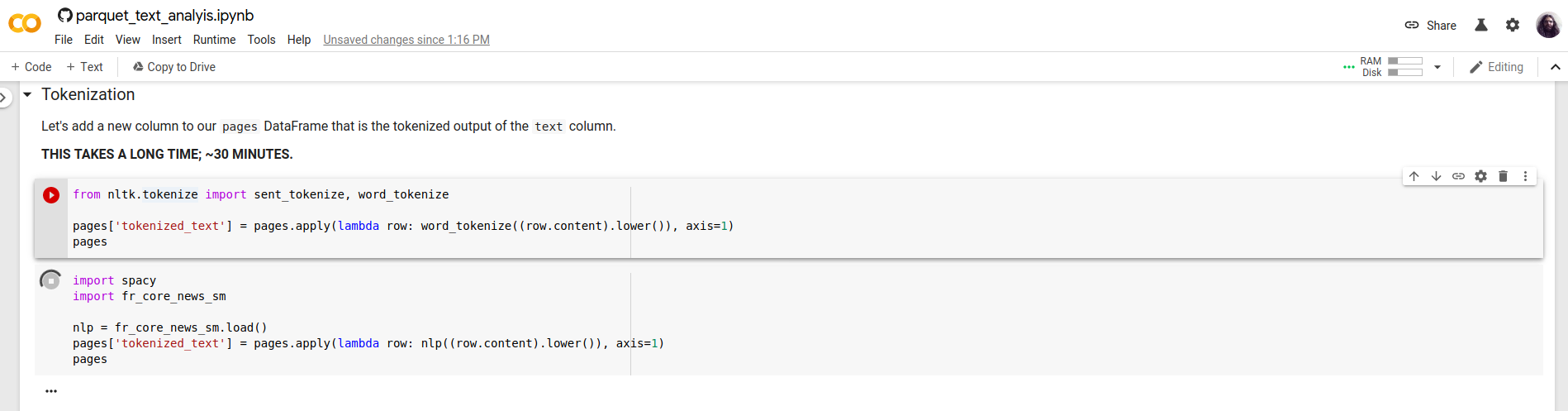
spacy.io looks really promising. Memory footprint appears to be a lot smaller than NLTK. But, I'm now well over an hour into executing tokenization on a DataFrame, and the NLTK option takes ~30 minutes. Overall, I'm just tying to find some balance between the valid issues @lintool raises, and the reality of taking a derivative from
Definitely lots of food for thought. Hopefully, we get some good feedback from researchers looking to use our derivative output for text analysis. ... Another option could be to just create an |
This comment has been minimized.
This comment has been minimized.
|
-1 on I think this is a good potential scenario for the derivatives of derivatives idea we discussed with Raymie. |
This comment has been minimized.
This comment has been minimized.
|
SpaCy is especially costly, but you can turn off certain modules, e.g. I agree with @lintool in spirit, that different scholars may want different tokenizations approaches, but very much believe in giving them something - it lowers the barrier to access and those with different needs can retokenize. I assume Colab only gives you one process? If you have a multi-core machine you can swap out pandas for dask, and then When using Another thing that might be worth considering is a dumb tokenize function, again in the spirit of giving something basically useful if not perfect. e.g. splitting on whitespace: |
This comment has been minimized.
This comment has been minimized.
|
By the way, I see that you use parquet. @bmschmidt smartly pointed out (massivetexts/htrc-feature-reader#8) that when you have repeating values in columns, like your mime type and crawl date columns, the order in which you sort the columns affects the compression size notably - even when using |
This comment has been minimized.
This comment has been minimized.
|
@organisciak tried the @lintool, et al., quick testing with PySpark and MLlib in Colab seems to moving a lot quicker that just plain Pandas and NLTK. If researchers are going to use the CSV or Parquet output of As I'm hacking on this notebook, and thinking about the feedback, if a consumer of the output of All this for archivesunleashed/notebooks#4 @ianmilligan1 |
This comment has been minimized.
This comment has been minimized.
|
+1 on language id |
This comment has been minimized.
This comment has been minimized.
|
Seeing no more discussion, I'll mark this as resolved with bc0d663 |
Currently
.webpages()creates a DataFrame with the following columns:crawl_dateurlmime_type_web_servermime_type_tikacontentThe
contentcolumn is the full text of the page, with HTTP headers, and HTML removed.In experimenting with full-text analysis in the parquet_text_analyis.ipynb, we add some additional column via
nltkfor tokenized words, and tokenized text word count.The tokenization process is pretty intensive. It takes around 30 minutes to complete in the example notebook, with the banq dataset. It also nearly exhausts the ~25G of RAM that is allotted via Colab.
So, instead of doing this post, why don't we consider doing this upfront in
.webpages()? The Spark MLlib has a tokenizer, and a few other options. Since I'm not a text analysis expert, and it'd just be stabbing in the dark tossing in new columns, let's get a sense of what would actually be useful.Check out this, and let us know what else would be useful out of the box in
.webpages()DataFrame.