Join GitHub today
GitHub is home to over 50 million developers working together to host and review code, manage projects, and build software together.
Sign upJava 11 support #356
Closed
Java 11 support #356
Comments
|
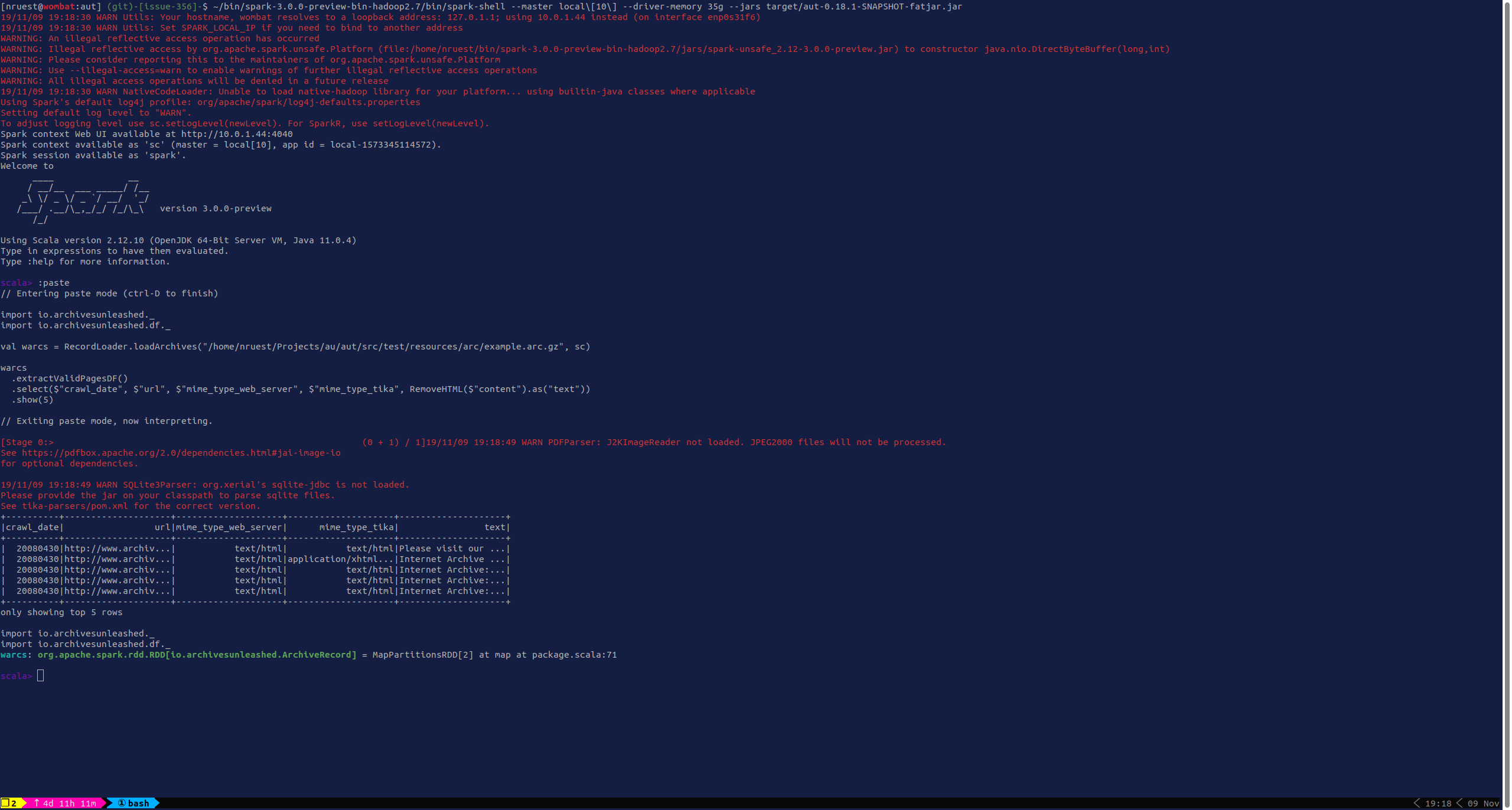
Getting closer to Spark 3.0.0! |
ruebot
added a commit
that referenced
this issue
Nov 9, 2019
|
Successful build: Successful Spark 3.0.0-preview load with BUT! We're broken somewhere: I'll have to dig in more later. |
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
|
Successful run here: 06764f7!!
|
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
ruebot
added a commit
that referenced
this issue
Nov 10, 2019
I'll get the branch updated shortly. |
|
Resolved with: 59b1d4e |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
From the Apache Spark mailing list:
We'll align with Apache Spark here on Java 11 support. Once we have a Spark release with Java 11, I'll pivot to getting
autstable with Java 11.