Join GitHub today
GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together.
Sign upPDF binary object extraction #302
Comments
 ruebot
added
enhancement
Scala
feature
DataFrames
labels
ruebot
added
enhancement
Scala
feature
DataFrames
labels
Jan 31, 2019
ruebot
added this to To do
in Binary object extraction
Jan 31, 2019
jrwiebe
added a commit
that referenced
this issue
Feb 1, 2019
 jrwiebe
moved this from To do
to In progress
in Binary object extraction
jrwiebe
moved this from To do
to In progress
in Binary object extraction
Feb 13, 2019
This comment has been minimized.
This comment has been minimized.
|
So, I think I have it working now building off of @jrwiebe's extract-pdf branch. I tested two scripts -- PDF binary extraction, and PDF details data frame -- on 878 GeoCities WARCs on tuna. PDF extractionScript import io.archivesunleashed._
import io.archivesunleashed.df._
val df = RecordLoader.loadArchives("/tuna1/scratch/nruest/geocites/warcs/9/*.gz", sc).extractPDFDetailsDF();
val res = df.select($"bytes").saveToDisk("bytes", "/tuna1/scratch/nruest/geocites/pdfs/9/aut-302-test", "pdf")
sys.exitJob $ time /home/ruestn/spark-2.4.3-bin-hadoop2.7/bin/spark-shell --master local[75] --driver-memory 300g --conf spark.network.timeout=10000000 --conf spark.executor.heartbeatInterval=600s --conf spark.driver.maxResultSize=4g --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.shuffle.compress=true --conf spark.rdd.compress=true --packages "io.archivesunleashed:aut:0.17.1-SNAPSHOT" -i /home/ruestn/aut-302-pdf-extraction/aut-302-pdf-extraction.scala 2>&1 | tee /home/ruestn/aut-302-pdf-extraction/logs/set-09.logResults Example output: https://www.dropbox.com/s/iwic5pwozikye5i/aut-302-test-925e8751447c08f2fbdf175e9560df7a.pdf Data frame to csvScript import io.archivesunleashed._
import io.archivesunleashed.df._
val df = RecordLoader.loadArchives("/tuna1/scratch/nruest/geocites/warcs/9/*gz", sc).extractPDFDetailsDF();
df.select($"url", $"mime_type", $"md5").orderBy(desc("md5")).write.csv("/home/ruestn/aut-302-pdf-extraction/df/9")
sys.exitJob $ time /home/ruestn/spark-2.4.3-bin-hadoop2.7/bin/spark-shell --master local[75] --driver-memory 300g --conf spark.network.timeout=10000000 --conf spark.executor.heartbeatInterval=600s --conf spark.driver.maxResultSize=4g --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.shuffle.compress=true --conf spark.rdd.compress=true --packages "io.archivesunleashed:aut:0.17.1-SNAPSHOT" -i /home/ruestn/aut-302-pdf-extraction/aut-302-pdf-df.scala 2>&1 | tee /home/ruestn/aut-302-pdf-extraction/logs/df-set-09.logResults $ wc -l set-09.csv
189036 set-09.csv
$ head set-09.csv
http://www.ciudadseva.com/obra/2008/03/00mar08/sombra.pdf,application/pdf,fffe565fe488aa57598820261d8907a3
http://www.geocities.com/nuclear_electrophysiology/BTOL_Bustamante.pdf,text/html,fffe1be9577b21a8e250408a9f75aebf
http://ca.geocities.com/stjohnnorway@rogers.com/childrens_choir.pdf,text/html,fffdd28bb19ccb5e910023b127333996
http://ca.geocities.com/kippeeb@rogers.com/Relationships/Tanner.pdf,text/html,fffdd28bb19ccb5e910023b127333996
http://www.scouts.ca/dnn/LinkClick.aspx?fileticket=dAE7a1%2bz2YU%3d&tabid=613,application/pdf,fffdb9e74a6d316ea9ce34be2315e646
http://www.geocities.com/numa84321/June2002.pdf,text/html,fffcad4273fec86948dc58fdc16b425b
http://geocities.com/plautus_satire/nasamirror/transcript_am_briefing_030207.pdf,text/html,fffcad4273fec86948dc58fdc16b425b
http://mx.geocities.com/toyotainnova/precios.pdf,application/octet-stream,fffc86181760be58c7581cd5b98dd507
http://geocities.com/mandyandvichy/New_Folder/money.PDF,text/html,fffc00bae548ee49a6a7d8bccbadb003
http://uk.geocities.com/gadevalleyharriers/Newsletters/_vti_cnf/Christmas07Brochure.pdf,text/html,fffbc9c1bcc2dcdd624bca5c8a9f1fc0Additional considerations
|
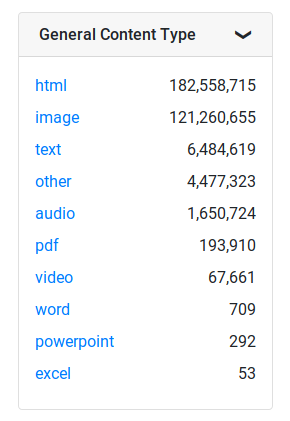
This comment has been minimized.
This comment has been minimized.
|
I'm not too concerned with credit for the commit, but I'm happy to make the PR. I would eventually like to put Tika MIME type detection back in, so we can find PDFs served without the correct type declaration. I'm running the same script on tuna with |
This comment has been minimized.
This comment has been minimized.
|
time... guess who didn't save it in the log file? I want to say it was around 8-10hrs for the PDF extraction, and around 12-14hrs for the csv. Oh, are you not getting the error with |
This comment has been minimized.
This comment has been minimized.
|
I was running an old version of the code, my last commit on the The job ran for 54 hours on tuna before getting killed. It extracted 19149 PDFs. I knew from past experiments that Tika MIME type detection was slow, but had forgotten quite how slow it is in our implementation. However, in searching for hints about improving performance I came across some tips from @anjackson in an issue discussion from 2015, which we never followed: using just Mime Magic detection (tika-core) and not container aware detection (tika-parsers), and instantiating Tika as a singleton object instead of with every call to DetectMimeTypeTika. I suspect the latter will have the greatest effect on performance. When I have a moment I'll try these changes and report back on the effect on performance. |
This comment has been minimized.
This comment has been minimized.
|
Simply instantiating Tika when the DetectMimeTypeTika singleton object is first referenced, and re-using the same object thereafter, resulted in an enormous performance boost. I believe @ruebot's above PDF extraction script ran in 7h40m. (Unfortunately, like @ruebot, I also didn't save my time stats.) I haven't yet tested using more limited tika-core detection, but this result is acceptable. The reason my job produced fewer files is that most of @ruebot's 144,757 were false positives. According to It appears the false positives in my job came from MIME types incorrectly reported by the web server. My Since web server MIME type reporting isn't reliable, and Tika detection isn't that expensive, I suggest if we're going to use |
This comment has been minimized.
This comment has been minimized.
tballison
commented
Jul 30, 2019
|
If Tika is causing any problems or surprises, please let us know on our mailing list: user@tika.apache.org +1 to (re-)using a single Parser/detector. They should be thread safe too. Will tika-app in batch mode meet your needs? That's multithreaded and robust against timeouts, etc. |
This comment has been minimized.
This comment has been minimized.
|
Most recent commit, we're back to the class conflicts we were having before I'll dig back into |
This comment has been minimized.
This comment has been minimized.
|
This works as a temporary solution: As I mentioned previously, this excludes parsers we would use for detecting Open Office and also Microsoft Office formats. When I wrote the afore-linked comment I stated that upgrading to Hadoop 3 would eliminate the underlying |
This comment has been minimized.
This comment has been minimized.
|
@jrwiebe that's not working on my end with |
This comment has been minimized.
This comment has been minimized.
|
Yes. |
This comment has been minimized.
This comment has been minimized.
|
I know why I'm getting the error again after the previous work. That previous solution used a work around on language-detector (for Guava versions), and we're using more of Tika here. So, we're back were we started. ...I'll loop back around to my Hadoop 3 branch. |
This was referenced Jul 31, 2019
This comment has been minimized.
This comment has been minimized.
|
Post-Hadoop3 wall, I've updated the extract-pdf branch with all the master updates, and went hacking again. This is where we're at: Even if I explicitly exclude commons-compress from But! Using the jar produced from the build on that commit plus the
So, I think we're back at the same place @jrwiebe was in #308, and all my research is just finding all his cloudera and StackOverFlow questions/comments from previous work Time to bark up the shading tree I guess. |
This comment has been minimized.
This comment has been minimized.
|
The shading approach would mean relocating I might have time to try this tomorrow if you don't do it first, @ruebot. |
This comment has been minimized.
This comment has been minimized.
|
Oh, I've done a wee-bit of Grade stuff back in Islandora/Fedora days. But, I'm at York tomorrow, so it's all you if you want. If we have to host something, feel free to create a repo, and we can get it transferred over to the archivesunleashed GitHub org. |
This comment has been minimized.
This comment has been minimized.
|
I might have a crack at it. Looking more closely at |
This comment has been minimized.
This comment has been minimized.
|
@jrwiebe I forked I think that is what we want? |
This comment has been minimized.
This comment has been minimized.
|
I fixed it. Shading The shading happens in the The artifact is built by JitPack. The shaded tika-parsers artifact artifact is included by changing the groupId in our POM to Testing:
Take note:
To do:We can discuss if using JitPack is preferable to using GitHub as a Maven repository. (I don't think we need to consider publishing it on the Central Repository. If people stumble upon our fork that's fine, but we don't want to be responsible for supporting it, right?) |
This comment has been minimized.
This comment has been minimized.
|
Success on my end!! Those singleton updates you made as well make this run insanely faster than before. Tested with df to csv, language extraction, and plain text extraction as well. Let's get a PR, and I'll squash it all down and merge it. I'm totally fine with JitPack. I wouldn't worry about doing a forked Maven release. Really nice work on this @jrwiebe, it was fun hacking on this one with you! |
ruebot commentedJan 31, 2019
Using the image extraction process as a basis, our next set of binary object extractions will be documents. This issue is meant to focus specially on PDFs.
There may be a some tweaks to this depending on the outcome of #298.