Join GitHub today
GitHub is home to over 50 million developers working together to host and review code, manage projects, and build software together.
Sign upEncoding management #428
Encoding management #428
Comments
|
@alxdrdelaporte thanks for creating the issue! There was an issue template, and we use that to collect some very useful information to troubleshoot the issue. Can you please provide some more information: Environment information
I have some sample WARC/ARCs from BAnQ that should help me troubleshoot, but if you could provide one that you're working with, that would be very helpful. |
|
@alxdrdelaporte this make sense? That's Spark 2.4.5 with the 0.50.0 release. What needs to be sorted out:
All that said, this is all web archives, and crazy stuff from the web end up in them. Text encoding is definitely going to be a giant reemerging thorn. |
|
Thanks for your answer @ruebot (and sorry for not following the issue template, I didn't see there was one) As my workplace is in lockdown until further notice all projects are on hold and I am not able to provide more information for now. I will as soon as I can (the only thing I will not be able to provide at all is a sample WARC file, because duplicating or processing data outside of the premises is strictly forbidden). |
|
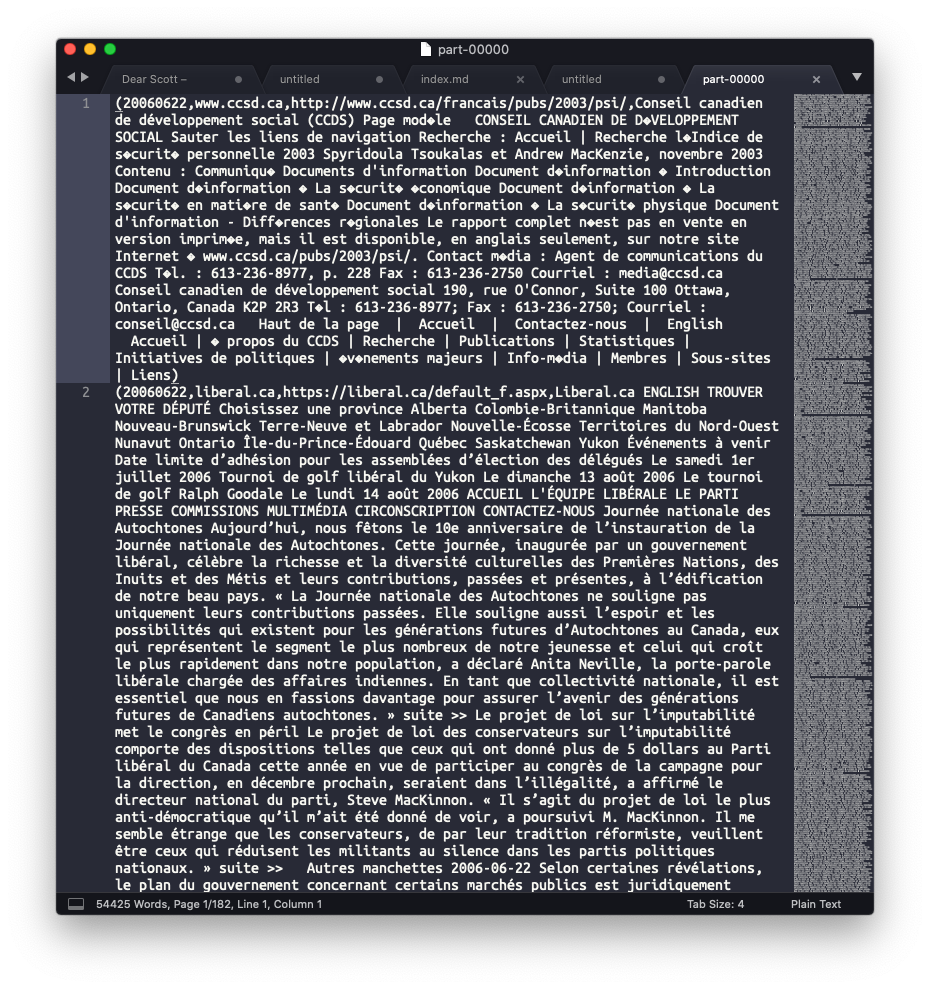
OK! I spent about an hour and a bit on this problem, and I am not sure how much closer I am. In our sample data WARCs, we have the issue of mixed encodings in the same WARC. We can see this here:
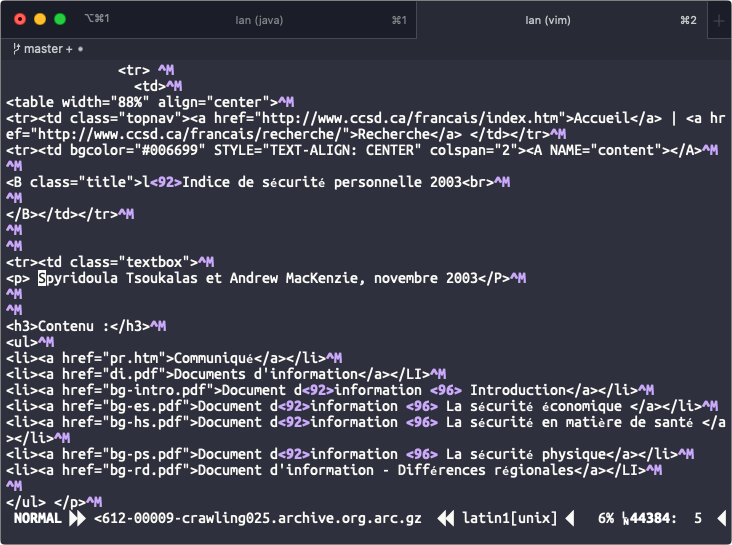
Looking at the WARC itself, we can see that the records that are not rendering properly are indeed encoded in ISO-8859-1. Looking at the WARC itself in vim, we can see the accents although we can see that even vim is having some trouble parsing them (note the super tiny é).
My thought was to try to convert the DataFrames to ISO-8859-1 and see if the results were usable. My script was thus: import io.archivesunleashed._
import io.archivesunleashed.df._
var data = RecordLoader.loadArchives("/Users/ianmilligan1/dropbox/git/aut-resources/Sample-Data/*.gz", sc)
.webpages()
.filter($"language" === "fr")
.select($"crawl_date", ExtractDomainDF($"url"), $"url", $"language", RemoveHTMLDF(RemoveHTTPHeaderDF($"content")))
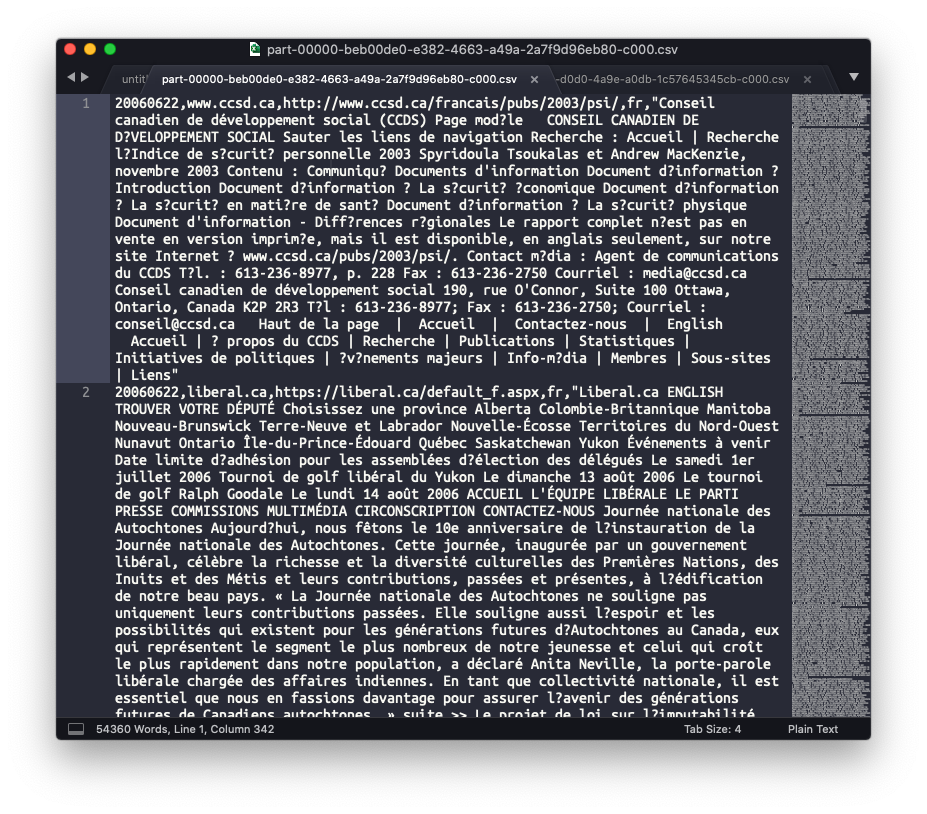
data.write.option("encoding","ISO-8859-1").csv("test2")Alas, that did not fix the ISO-8859-1 encoded file (changed the error characters to question marks for the most part), and indeed broke the properly rendered files as well.
So @ruebot, looks like the data is "good" in the WARC (in the sense that it is readable, even if it is in different encodings), but by the time we get to the I am probably the last person who should be digging into this, but hopefully this is helpful? |
|
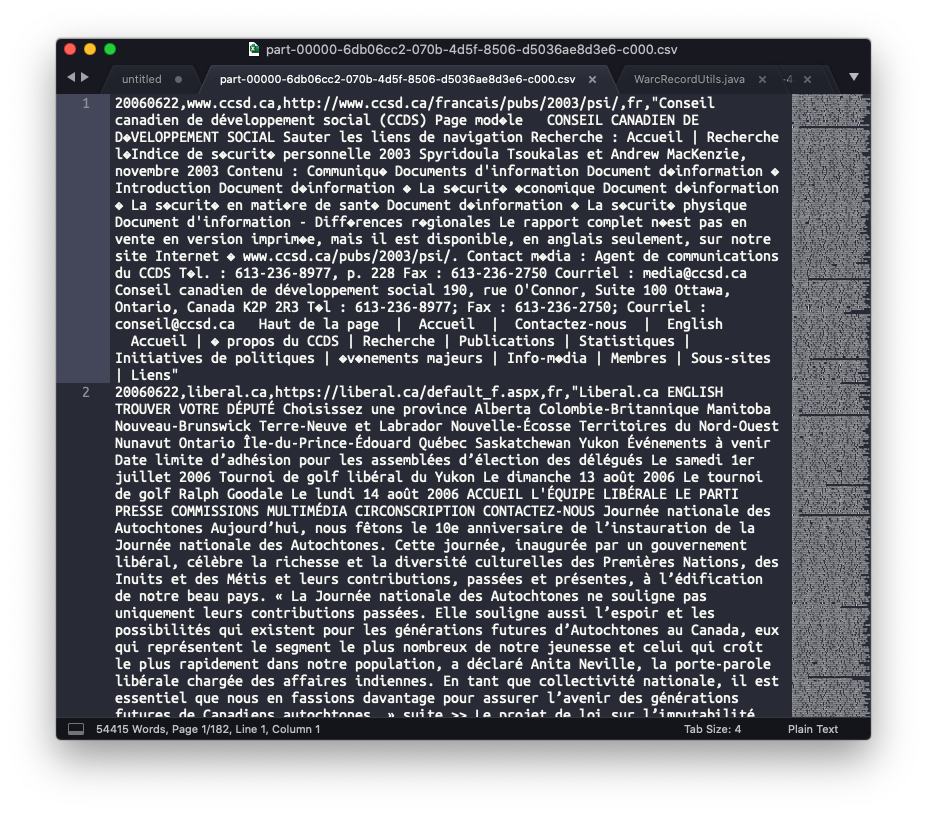
And I was curious, so I tried @greebie's idea of changing the
But even when in theory reading WARCs in using ISO-8859-1, the record theoretically encoded that way doesn't work.
|
|
Thanks @ianmilligan1! This is some good hacking and supporting documentation. It all dovetails really nicely with my digging. Without seeing @alxdrdelaporte's WARC, I'm going to hazard a guess that it has the same mixed encoding that many ARC/WARCs are going to have. Most likely the result of a bunch of wild web servers serving up a variety of encodings. Mircosoft web servers? Roughly, we're pulling the "content" from a ARC/WARC record as a raw byte array in Java, and then handing that off Scala to Looping back to my earlier comment, I'm honestly not sure this is something that @anjackson @tokee I'd assume y'all hit this hurdle before with |
|
Hi @ianmilligan1 - could you check if loading using UTF-8 works okay instead? The issue with .getBytes() as I understand it, is that it will use the default encoding, which can differ from OS to OS. Also -- just in case, you changed the encoding in all 3 places, including here, correct?: I think forcing to UTF-8 is a good idea at any rate. Might not solve this problem, but it may prevent other issues down the road. |
|
Thanks @greebie (hope you're well!). I can try w/ UTF-8 in a bit - but yes I did also try it in all three places as well (same results). |
|
Thanks. Social distancing isn't fantastic for my fashion sense, but so far we are doing okay. (Thank goodness.) |
|
Confirmed that the WARCWriter library saves as UTF-8 by default, so this problem likely only occurs when the warc has been saved in another encoding. |
|
Hi @alxdrdelaporte - hope you’re still saying safe and healthy amidst the global situation. Our team has looked at this issue quite a bit and ultimately our issue through sleuthing is that we’re running into problems with mixed-encoding ARC/WARCs: i.e. one server is encoding content in ISO-8859-1 (Latin1) and another in say UTF-8. We’ve tried a few different solutions and ultimately, short of doing encoding detection on each record – which would have performance implications as well - I think this might be out of scope for the Archives Unleashed Toolkit since the problem lies at the data coming into it. |
I am currently working on a project involving content extraction from a certain number of WARC archives.
I use Archives Unleashed Toolkit to extract plain HTML content (script below) and it works very well.
However I encounter a problem regarding the output file produced by this script: the webpages (mostly in French) extracted from the WARC archive do not all have UTF-8 as their original encoding, so some characters are not rendered properly in the output (and replaced by �).
For example :
nouvelle page consacr�e au 114�me bataillon de marche de chasseurs alpinsAs my research is mainly based on lexicon analysis, proper encoding and character rendering are an important matter.
I would be great if there was a way to deal with non-UTF encodings (such as windows-1252 or latin1) while extracting with AUT.